Message boards : Graphics cards (GPUs) : Big Maxwell GM2*0
| Author | Message |
|---|---|
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
http://wccftech.com/article/generation-graphics-prospects-nvidia-big-daddy-maxwell-16ff-ports/ | |
| ID: 38887 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
the 1st article wrote: The GK110 is roughly 550mm^2 and the limit of TSMC is at roughly 600mm^2. So can the GM200 exist on a 28nm Node? Absolutely, yes. Will it? Well, the consumer samples taped out a long time back, and they are sure as hell not on 16nm FinFET. Which makes sense to me. I edited the title, so that it doesn't imply GM2x0 would be made in 16nm FinFET tech. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 38890 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
http://devblogs.nvidia.com/parallelforall/increase-performance-gpu-boost-k80-autoboost/ | |
| ID: 38959 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
Lower Power Operating Points than GM204 or GK110B revision. If you ran GM204 at 550 - 850 MHz with appropriate voltage it would easily beat GK210's power efficiency. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 38979 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
If you ran GM204 at GK210 clocks: GM204 single is less than GK210 Double Flops. Once Big Maxwell specs are confirmed- this could be only full compute worthy Titan Maxwell (dual card also) until late 2016 early 2017 Pascal arch. | |
| ID: 38984 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
If you ran GM204 at GK210 clocks: GM204 single is less than GK210 Double Flops. What?! GK210 runs DP at 1/3 its SP performance, so it's equivalent to 2880/3 = 960 shaders. GM204 has 2048 shaders for SP, which actually perform more like 1.4*2048 = 2867 Kepler-Shaders. At similar clocks GM204 SP would be about 3 times as fast as GK210 DP. Any why are you talking about DP anyway? If you need DP and nVidia you're badly f*cked anyway, because nothing below an ultra-expensive Titan makes any sense. the amount of DP cores in gaming Maxwell doesn't matter, because performance would s*ck anyway. It's meant for compatibility, testing and debug, but not for pure number crunching. I know people are not aware of this and like to run Milkyway on nVidia cards, but that doesn't change the fact that DP-crunching on either Kepler or Maxwell, or mainstrea-Fermi for that matter, is a pretty bad idea. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 38996 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
CUDA7 (pre-production release) will be here around the new year. Production release near April. (NVidia last couple Major CUDA releases have been early in the year) Current CUDA driver is 6.5.30 | |
| ID: 39029 | Rating: 0 | rate:
| |
 Retvari Zoltan Retvari ZoltanSend message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
|
price | price | Total
USD | per core | DP
250W TDP 2880 core Titan Black 1000 | 34.7c | 960 (64 DP SMX enabled)
375W TDP 5760 core Titan-Z 1500 | 26c | 1920 (64 DP SMX enabled)
300W TDP 3072 core GTX 690* 519 | 16.9c | 128 (8DP core per SMX)
250W TDP 2880 core GTX 780ti* 419 | 14.5c | 120 (disabled 64DP SMX- driver enables 8 per SMX)
225W TDP 2304 core GTX 780* 319 | 13.9c | 96 (disabled 64DP SMX- driver enables 8 per SMX)
165W TDP 2048 core GTX 980 549 | 26.8c | 64 (4 per SMM)
145W TDP 1664 core GTX 970 329 | 19.7c | 52 (4 per SMM)
230W TDP 1536 core GTX 770* 239 | 15.5c | 64 (8 per SMX)
195W TDP 1536 core GTX 680* 229 | 14.9c | 64 (8 per SMX)
170W TDP 1344 core GTX 670* 179 | 13.3c | 56 (8 per SMX)
140W TDP 1344 core GTX 660ti* 159 | 11.8c | 56 (8 per SMX)
170W TDP 1152 core GTX 760* 159 | 13.8c | 48 (8 per SMX)
140W TDP 960 core GTX 660 134 | 13.9c | 40 (8 per SMX)
110W TDP 768 core GTX 650ti* 89 | 11.5c | 32 (8 per SMX)
60W TDP 640 core GTX 750ti 129 | 20.1c | 20
55W TDP 512 core GTX 750 109 | 21.2c | 16
25W TDP 384 core GT 630 37 | 9.4c | 16
*=refurbished
I've just made your spreadsheet more readable. | |
| ID: 39031 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
I've just made your spreadsheet more readable. Gentlemanly of you For all those spreadsheet programs available: MS notepad doesn't organize! | |
| ID: 39032 | Rating: 0 | rate:
| |
|
Jozef J Send message Joined: 7 Jun 12 Posts: 112 Credit: 1,118,845,172 RAC: 0 Level Scientific publications | |
|
http://www.chiploco.com/nvidia-geforce-gtx-titan-ii-3072-cores-12gb-memory-36760/ | |
| ID: 39308 | Rating: 0 | rate:
| |
|
Jozef J Send message Joined: 7 Jun 12 Posts: 112 Credit: 1,118,845,172 RAC: 0 Level Scientific publications | |
|
http://www.tweaktown.com/news/42269/amd-nvidias-next-gen-gpus-delayed-supply-constraints-blamed/index.html | |
| ID: 39313 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester  Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
http://www.tweaktown.com/news/42269/amd-nvidias-next-gen-gpus-delayed-supply-constraints-blamed/index.html There is a typo in that report, they said Apple instead of AMD; "so that leaves Apple and NVIDIA with a very limited supply of 20nm dies". Basically TSMC will be busy making 20nm Qualcomm SoC's, so NVidia and AMD will have to wait their turn. This isn't such a bad thing - AMD and NVidia need bigger dies. That means TSMC will have refined the process by the time its AMD and NVidia's turn. ____________ FAQ's HOW TO: - Opt out of Beta Tests - Ask for Help | |
| ID: 39314 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Once Big Maxwell specs are confirmed- this could be only full compute worthy Titan Maxwell (dual card also) until late 2016 early 2017 Pascal arch. Kelper's HPC boards will reign until late 2016/early 2017 due to Maxwell's weak DP core structure (1 DP core in every 32c subset block and no 64bit/8byte banks like Kelper) The GeForce Titan Maxwell (4 DP per 32c subset/32DP per SMM) will be the full feature compute Maxwell with less DP cores (768) compared to Kelper's 960/896/832 DP64 line-up unless GM2*0 has 64DP for every SMM (1/2ratio) This will keep Titan prices higher unless AMD 2015 offering +20% GM2*0. The GTX 960(ti) will feature [3] different dies. (8SMM/10SMM/12SMM) The 8SMM could be 70-100TDP with Ti variants being 100-130TDP. | |
| ID: 39350 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
@eXaPower: let's wait and see, so far we've only got rumors (although lot's of it). I'm sure the biggest Maxwell chip will be better at DP than GK210. The market and profit margin for such chips in the form of Teslas and Quadros is just too large for nVidia to ignore. For gaming they could just as well give us 2 GM204 on one card instead of creating a new flag ship chip. And don't forget the higher efficiency of Maxwell per shader - some of this will also apply to DP once there are a lot of DP-capable shaders. | |
| ID: 39354 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
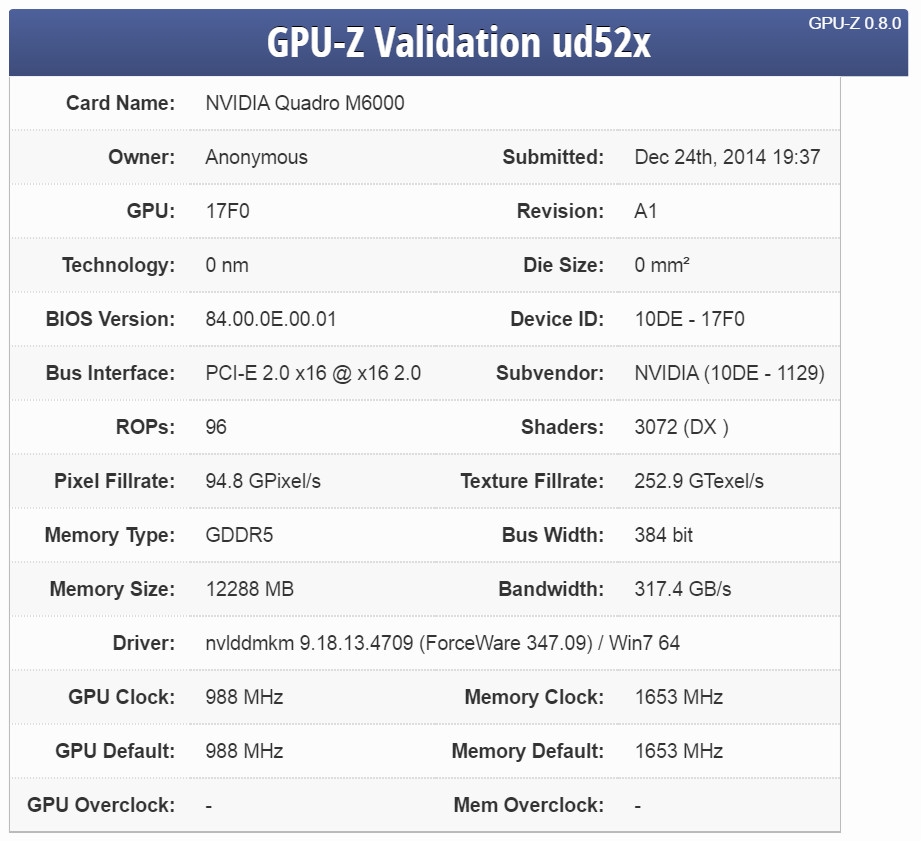
A GM200 Quadro been spotted in GPU-Z database: 3072CUDA/192?256?TMU/96ROPS. If "M6000" is indeed the replacement for K6000 than DP performance will be near 1.7 Teraflops. A forth coming announcement will be this month. (Could include a CUDA7 toolkit) | |
| ID: 39368 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
| |
| ID: 39371 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
0nm is smaller than expected ;p Ouch - there are going to be some serious short channel effects with such small structures! I heard the chip is going to be called Atom, but they're still fighting with Intel in court over it. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 39376 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
This raises the question of 20nm, 16nm and thus release dates; I really didn't expect a 20nm anything from NV any time soon, and I still don't... You're right- Nvidia will be 16FinFet. Speculation: The first batch of GM200 is likely 28nm unless TSMC has an excellent recipe of being extremely silent with mis-information spread and 16nm yield is way above initial expectations. 20nm is for low power SOC (phones) and maybe ~75TDP AMD APU's. AMD could stay at 28nm and then go Global Foundries 14nm. We might be stuck at 28nm until next year. (28nm for Maxwell GPU worked out. Running FP32 full bore on Air cooling has temps below 65C and even 55C when properly tuned.)
For 24/7 compute (here) the Titan-Z Temps that I've seen are little high as are some GTX690's. Maxwell's core structure is able to keep silicon temps lower than Kelper- a dual GM204 at 300TDP is well with-in engineering. I'm curious to see how Maxwell is affected once more DP cores are added. | |
| ID: 39377 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
3DCenter also commented on "Big Maxwell has no DP units". They've got 2 rather convincing points: don't forget the higher efficiency of Maxwell per shader - some of this will also apply to DP once there are a lot of DP-capable shaders. I still stand by this statement. However, most of Maxwells increased efficiency per Shader comes from the fact that the super-scalar shaders are not unused most of the time. But in DP there are fewer shaders anyway, so Kepler has not extra tax to pay for unused super-scalar units. Maxwell couldn't improve on this.. and the remaining benefits like better scheduling were probably not worth the cost for nVidia. Thereby I mean the cost of outfitting GM210 with enough DP units to make it faster than GK210. This would probably have made the chip too large with 24 SMM, which means they would have needed to reduce the number of SMMs and sacrifice SP / gaming performance. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 39385 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
3072 Maxwell Shaders with additional DP units may simply have been too large for 28 nm, where ~600 mm² is the feasible maximum TSMC stretched the limit: GM200 at 600 mm². Compute Capability for GM200 is unknown. It won't be 3.5/3.7 as this designation is for Kelper. C.C 5.5 is possible. Searching many CUDA7 C/C++ header for DP GM200 clues.... Maxwell has a 20nm GPU: TegraX1 (2SMM/[4] A-53 [4] A-57 ARM cores) I wonder if Nvidia sneaks a 20nm High performance GPU into the mix? GM200-400-A1 Quadro is confirmed at 28nm. This raises the question if GM200 will make into the GeForce line-up. A cut down version at 2688cores (21SMM) is possibly the first Geforce released. The first GK110 Tesla and original Titan were cut. Titan's are becoming rarer by the minute. Prices all over the place in the US. A side note: TSMC is having a lot trouble with 16nm FinFet - losing QUALCOMM to Samsung. 2H 2016 is now when high performance wafers could be ready for full scale production. 3Q of 2015 was the initial estimate for 16nm. | |
| ID: 39500 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
CC5.5 would make sense. | |
| ID: 39520 | Rating: 0 | rate:
| |
|
RaymondFO* Send message Joined: 22 Nov 12 Posts: 72 Credit: 14,040,706,346 RAC: 0 Level Scientific publications | |
|
EVGA has this "Kingpin" (GTX 980 classified version) that has three (3) power inputs (8pin + 8pin + 6pin) available for pre-order starting 01 Feb 2015 for existing EVGA customers. To qualify as an existing EVGA customer, you must have already registered at least one (1) or more EVGA products on their web site. | |
| ID: 39521 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
That Kingpin is not big Maxwell. And pretty useless, unless you want to chase world records with deep sub-zero temperatures ;) | |
| ID: 39544 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
3DCenter also commented on "Big Maxwell has no DP units". They've got 2 rather convincing points: ETA: excellent post ---- I've been following this ever evolving rumor more closely and surprisingly: 3Dcenter has again "confirmed" Double Precision compute is severely limited compared to enabled GK110. It's possible the DP rumor is purposeful misinformation distortion by an insider being paid to create uncertainty. Deceptive tactics are nothing new within industries. I'm patiently awaiting trusted compute programs to PROVE weak DP performance. There will be a pile of intriguing bait click rumors before the launch of AMD or NVidia's 28nm "flagship". The stacked HBM 4096bit bus hoopla about AMD 300 series dampens NVidia's secretive approach. Engaging in a continuously defensive posture about products allows for more rumors to crop up - even with a rising market share. (Never mind the 970 internal transmits issue topping out at 5% return rate) Will NVidia quell GM200 rumors or wait for real world performance results? The Professional market a different domain than game[ing] Even if Maxwell DP matches Kelper: C.C3.5/3.7 will reign HPC until 16nm Pascal with possible ARM cores. Which engineering or science sector will upgrade from GK110 to GM200? A handful? An upgrade from Fermi to Maxwell is reasonable - unless of course: awful DP. At this point waiting for Pascal seems logical. C.C3.5 well engineered structure is long in tooth (higher clocks and 32core sub-sets blocks are one of reasons Maxwell is faster for certain paths) C.C3.0 is still a decent Float performer - C.C5.0/5.2 has an edge for integer workloads. The GPU Technology Conference in March is supposedly where the Quadro/Titan2/980ti/990 will be announced. If GM200 limited FP64 workload is exposed - what's NVidia thinking behind building (besides profit) a supposedly professional market GPU (DP CUDA accounts for over 60%) - whose major compute component is suddenly missing or underwhelming? As skgiven mentioned: what's the purpose of GM200 if DP is shunned? To be a +225W TDP FP32/int32/gaming GPU that's +20% a GTX780ti or 980? A GeForce with weak DP is understandable: each successive GP generation has lessened DP performance. It's concerning and mad to revise the Tesla/Quadro/Titan brand backwards by offering less compute options than prior generations. Without an impressive 1/2 ratio: the advantage for DP compute workloads is (1/4r) minimal or inherently less with Maxwell's 1/32 ratio. GK110 plenty capable even if GM200 1/4 supplies similar DP FLOPS. GK110 features became mainstream in all Maxwell's - nary an upgrade. Maxwell adds a few gaming enhancements and HEVC advances. GM206 became the first GPU to adapt HDMI2.0 and full 265 video rendering. Kelper video SIP block is the first generation. GM107 second revision while GM204 is third with GM206 being the fourth revision. GM200 SIP will most likely be similar to GM206. | |
| ID: 40152 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
Thanks, eXa. Regarding the question:"Why GM2*0 without DP?" I think it's actually rather simple: | |
| ID: 40216 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
http://anandtech.com/show/9049/nvidia-announces-geforce-gtx-titan-x No confirmation regarding double precision performance. More information will be released during the NVIDIA GPU Technology Conference (possible launch) in a couple weeks. | |
| ID: 40353 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Titan X will have 8 billion transistors, 3,072 CUDA Cores, 12 GB GDDR5 memory and will be based on Maxwell. | |
| ID: 40404 | Rating: 0 | rate:
| |
|
I thought the Big Maxwell should be really fast and got its own one or more RPM chip(s) so that it need less interaction with the CPU. | |
| ID: 40410 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
http://videocardz.com/55013/nvidia-geforce-gtx-titan-x-3dmark-performance No SP/DP/Integer compute benchmarks as of yet. The performance comparison mentioned: 3D mark (extreme) Firestrike benchmark. An overclocked (1200MHz) TitanX is nearly on par with a 5760 CUDA TitanZ and 5632 GCN AMD295x. Compared to overclocked GTX980 - the Firestrike score is +20%. Reported base clock is 1002MHz which translates into 6TeraFlops for 32bit - 1.4TeraFLOPS more than a 1126MHz reference GTX980. | |
| ID: 40416 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Based on those specs the Titan X should be at least 20% faster than a Titan Black which in turn would mean it's at least 25% faster than a GTX980. | |
| ID: 40426 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Hopefully the release of the Titan X will drive down the prices of the GTX980 and GTX970. GM204 prices have fluctuated from below MSRP to way above - steadily selling since. AMD will be releasing new high performance GPU's with-in a few months. When AMD future core performance is above/better than NVidia - prices move downward even further. In terms of performance/Watt it's a clear winner over the Titan Black. Basically >25% extra performance for the same power draw. Reference Kelper/Maxwell Titan's clock (+-166MHz/836-1002MHz) difference equals to +1Tera (32bit) code instructions performance improvement. 5~TeraFLOPS 32bit performance for reference 2688/2880 CUDA GK110. 6.1Tera performance for 3072 CUDA GM200 32bit at 1002MHz base clock. ~6Tera 32bit instruction output is possible on a overclocked GK110 Titan. ~7TeraFLOPS = TitanX +1200MHz clock For 32bit - the TitanX has an advantage. If GM200 SP/DP ratio is the standard Maxwell 1DP core in every 32c subset (4DPper128SMM) than overall performance/watt is slewed. I would compare the TitanX overall compute capabilities to a (120DPc) GTX780ti rather than 896 or 960 DP64 core enabled GK110 Titan. Will GM200 be 64bit worthy? GM200's 64bit core/memory structure (performance) is unknown. Whitepaper analysis has yet to be revealed. GM107/204/206 Maxwell's 64bit C.C5.0/5.2 lacks the faster C.C3.0/3.5 Kelper warp/thread 64bit shared memory pipeline. (GK210) C.C3.7 upped to 128 bit data path. See CUDA performance guide. Combining 32bit/64bit - GM204/206/107 fewer total DP cores (C.C5.0/5.2) executes less - lagging behind C.C3.0/3.5/3.7 advanced 64bit code instruction output. GK110 Kelper slower clocks (DP64 driver setting) point to 896/960 Titan 64bit cores energy management requirement. 32bit cores operate at lower wattage. Silicon with less 64bit cores will being down circuitry energy. So far - Maxwell trades less DP cores for higher 32bit core clocks. A 64DP SMX power draw shifts - hard to pin down amount of energy the core is being fed while computing DP. GM200 raster operations 96(ROP) performance (Game Graphics) doubled compared to Kelper's 48. Faster [24] SMM Polymorph engine(s). GM200's revised Texture Mapping Units (192) same number as [GTX780] - 48/32 less than first generation 15SMX Titan (Black) and 14SMX Titan. | |
| ID: 40430 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
GM200 officially launches today. GTC starts at 9amPST/12EST. https://registration.gputechconf.com/form/session-listing Reference GM200 Titan PCB (NVTTM) similar to GTX690/770/780/780ti/Titan/Black/TitanZ 8 power phase (6+2) design with 6 MOSFETS and a OnSemi NCP4206 voltage chip. Layout is slightly different from GK110 or GK104. GM204/206 overclocks really well: the GM200 will be capable of (1400-1500Mhz). | |
| ID: 40490 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
You can watch the presentation live now, | |
| ID: 40491 | Rating: 0 | rate:
| |
|
Mmm not a bad price and it looks more promising then I thought. I will start saving money so I can buy one in fall. | |
| ID: 40494 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
dp cut down to 0.2TFlops Very disappointing DP performance for a Flagship. Hat tip to 3D center in Germany for correctly predicating horrid DP. GK110/GK210 (C.C3.5/3.7) is still the HPC compute flagship of NVidia. GM200 is a compute downgrade when factoring in all aspects of how a GPU creates. For anyone who writes in something other then 32bit: GM200 is not the GPU to buy. GM200 at 1000$ with Intel Broadwell DP performance is outrageous. Nvidia could have used an Ultra/985/1*** series moniker instead of Titan and priced at 649$. Titan Moniker is now tainted. (The future ti version of GM200) at the reasonable price of 649$ with similar performance as GM200 "Titan" - being the replacement for 32bit overall GTX780ti compute capabilities which launched at 699$. GM200 marketing as the Titan replacement is nonsense because loss of GK110 DP compute features. More gaming revisions less compute options. Many practical long term GPU usage options exist along with games. (GM200 ti release will be sometime in June when AMD shows off their potent GPU's.) NVidia will also release GM cut dies near AMD's launch. Maxwell's overall DP has been exposed as weak: [32] 32bit memory banks rather [32] 64bit banks like Kelper. The GTX480/580/780 all have similar DP performance as a Maxwell "flagship". For here: GM200 (a larger GM204/same Compute set) --- FP32 ACEMD performance will be outstanding. Whomever owns the DP enabled GK110 compute card Titan - now has a GPU with longstanding value that will stay until 16nm Pascal or beyond. When AMD 4096 core/64CU 390X flagship offers the Hawaii 1/8 ratio (512DP) 8DP per 64C CU -- AMD revised cores are little short of GK110 C.C3.5 complete compute arch. 2048c/32CU Tahiti's 1/4 ratio 512DP cores (16DPper64CU) has given NVidia trouble in some DP markets. CUDA's DP market share - being eroded by OpenACC/OpenMP is eminent if Pascel DP is slow for a "flagship" GPU. A decline of CUDA DP will be a foregone conclusion. (Doubling the amount of ROPS). For graphics: this an upgrade for Maxwell filtering and display advances. Although Vulcan (OpenGL) and DirectX Kelper (vertex/pixel/tessellation/geometry) unified shaders work with the same feature levels as Maxwell. The revised (8TMUper128SMM) GM200 higher clocked Texture Mapping Units are faster compared to Kelper. 192 for 3072 GM200 cores. The (16TMUper192SMX) GK110 consists of 2304/192 > 2688/224TMU > 2880/240. http://anandtech.com/show/9059/the-nvidia-geforce-gtx-titan-x-review/15 http://www.guru3d.com/articles_pages/nvidia_geforce_gtx_titan_x_review,10.html http://www.tomshardware.com/reviews/nvidia-geforce-gtx-titan-x-gm200-maxwell,4091-6.html Density of GDDR5 12GB heats up: temps higher than core or VRM temps. | |
| ID: 40499 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
Mmm not a bad price and it looks more promising then I thought. I will start saving money so I can buy one in fall. TJ, this card is 50% more hardware than a GTX980 for about double the price. That's a rather bad value proposition! While I generally support the argument of "fewer but faster GPUs" for GPU-Grid, this is too extreme for my taste. Better wait for AMDs next flag ship, which should arrive within the next 3 months. If it's as good as expected at priced around 700$, nVidia might offer a GTX980Ti based on a slightly cut-down GM200 at a more sane ~700$. Like the original Titan and GTX780Ti - the latter came later but with far better value (for SP tasks). @eXa: don't equate "compute" with DP. Of course GM200 is weak if you need serious DP - but that's no secret. NVidia knows this, of course, and has made GK210 for those people (until Pascal arrives). For any other workload GM200 is a monster and mostly a huge improvement over GK110. There are a lot of such computing workloads. Actually, even if you have a DP capable card you'd still be better off if you can use it in SP mode. If this thing is worth the "Titan" name is really irrelevant from my point of view. Few people bought the original Titan for it's DP capabilities. Fine.. they'll know enough to stick to Titan and Titan Black until Pascal. But most are just using them for games & benchmarks. They may want DP, but they don't actually need it. GM200 at 1000$ with Intel Broadwell DP performance is outrageous. Only if you measure it by your expectations, formed by the 1st generation of Titans. And don't forget: including DP units in GM200 would have made it far too big (and made it loose further clock speed & yield, if it was possible at all). Or, at the same size but with DP the chip would have had significantly less SP shaders. The difference to GTX980 would have been too small (such a chip would still loose clock speed compared to smaller Maxwells) and hence a tougher sell for any market that the current GM200 appeals to. I admit I didn't believe the initial rumor of GM200 without DP. But now it does make a lot of sense. Especially since most Maxwell improvements (keeping the SP shaders busy) wouldn't help in DP, because Kepler was never limited here (in the same way) as it is in SP. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 40581 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
|
When will the GPUGrid app support BigMaxwell? | |
| ID: 40592 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
I guess nobody has a GTX Titan X attached and working yet, otherwise it would appear in Performance | |
| ID: 40593 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Does anyone have such card to test the current client? Performance Tab: TitanX -- NOELIA_1mgx (short) | |
| ID: 40603 | Rating: 0 | rate:
| |
|
MJH Project administrator Project developer Project scientist Send message Joined: 12 Nov 07 Posts: 696 Credit: 27,266,655 RAC: 0 Level Scientific publications | |
When will the GPUGrid app support BigMaxwell? Soon, but not imminently. AFAIK, no one's attached one yet. (It's working here in the lab).
High roller! I'd have throught 980s would be more cost effective? | |
| ID: 40604 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
When will the GPUGrid app support BigMaxwell? FYI, it's working now (on Windows 8.1). Here is a short workunit processed successfully on a Titan X. (Thanks to eXaPower for pointing it out) I'm planning to sell my old cards (GTX670s and GTX680s), They are. But as I will apparently loose my 2nd place on the overall toplist, I'd like to do it in a stylish manner. So I shall continue to have the fastest GPUGrid host on the planet at least. ;) | |
| ID: 40608 | Rating: 0 | rate:
| |
|
[CSF] Thomas H.V. DUPONT  Send message Joined: 20 Jul 14 Posts: 732 Credit: 105,130,366 RAC: 275,493 Level Scientific publications | |
|
https://twitter.com/TEAM_CSF/status/580627791298822144 | |
| ID: 40609 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
--- NOELIA_1mg --- (980) began work -- Titan X finished it. Host# 196801 resultid=14020924 | |
| ID: 40613 | Rating: 0 | rate:
| |
--- NOELIA_1mg --- (980) began work -- Titan X finished it. Host# 196801 resultid=14020924 And we see the Windows limitation of four again...only 4GB of that awesome 12 is recognized and used. I think I will wait for the "real" big Maxwell with its own CPU. At this time 1178 Euro for a EVGA one is too much for my wallet at the moment. ____________ Greetings from TJ | |
| ID: 40617 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
MJH wrote: I'd have thought 980s would be more cost effective? Yep, and even more so the GTX970's (see SKs post). @TJ: don't worry about the memory, ~1 GB per GPU-Grid task is still fine. And don't wait for any miraculous real big Maxwell. GM200 is about as bis as they can go on 28 nm, and on Titan X it's already fully enabled. I'd expect a cut-down version of GM200 at some point, but apart from that the next interesting chips from nVidia are very probably Pascal's. And about this "integrating CPU" talk: the rumor mill may have gotten Tegra K1 and X1 wrong. These are indeed Kepler and Maxwell combined with ARM CPUs.. as a complete mobile SoC. Anything else wouldn't make much sense in the consumer range (and AMD is not giving them any pressure anyway), so if they experiment with GPU + closely coupled CPU I'd expect this first to arrive together with NVlink and Open Power server for HPC. And priced accordingly. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 40618 | Rating: 0 | rate:
| |
Thanks for the explanation. Haha I don't worry about the memory but crunchers on Windows pay quite a lot for 8GB that cannot be used with this new card. It depends on my financial conditions but I think I wait for a GTX980Ti, but not before fall, as summer turns to warm for 24/7 crunching (without AC). ____________ Greetings from TJ | |
| ID: 40624 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
But as I will apparently loose my 2nd place on the overall toplist, I'd like to do it in a stylish manner. So I shall continue to have the fastest GPUGrid host on the planet at least. ;) (ROBtheLionHeart) Overclocked 780ti (XP) NOELIA's are a hair faster than you're mighty 980 (XP). Rarely a sight not to see you (RZ) with the fastest times! The Performance Tab engaging comparative tool for crunchers a new way to learn about work units and expected GPU performance. Current Long run only Maxwell RAC per day (crunching 24/7) including OS factors:
skgiven's Throughput performances and Performances/Watt chart -- relative to a GK110 GTX Titan.
| |
| ID: 40628 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Roughly 56% faster than a Titan, | |
| ID: 40635 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Roughly 56% faster than a Titan. As you expected for GPUGRID ACEMD: an increase of ~60% Suggests it boosts to 1190MHz but quickly drops to 1163MHz (during stress tests) and that it's still dropping or increasing in steps of 13MHz, as expected. 1190 is ~15% shy of where I can get my GTX970 to boost, so I expect it will boost higher here (maybe ~1242 or 1255MHz). Apparently the back gets very hot. I've dealt with this in the past by blowing a air directly onto the back of a GPU and by using a CPU water cooler (as that reduces radiating heat). 12Gb of Memory is really hot (over 100C) for prolong use. As a fan blowing on the back helps- Will a back plate lower temps with such density or hinder by holding more heat to those outer (opposite the heat sink) memory pieces? Custom Water block (back) plate? (Full CPU/GPU water cooling loop) Only air cooling at 110C: down clocking of GDDR5 with a voltage drop could help. Longevity concern: can GDDR5 sustain +100C temps? I think the power techup website (Titan X review) shows the model number to reference. GDDR5 rated at 70C/80C/90C? Over bound Temperatures will certainly impact long term overclocking and boost rate prospects. | |
| ID: 40638 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Cooling 12GB appears to be a big issue and it's likely hindering boost and power consumption, but without the 12GB it wouldn't be a Titan, saying as it doesn't have good dp. | |
| ID: 40642 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Many voltage controllers are dumb with VID lines only. (Titan X) No i2C support. Driver read only rather than software. There are few a PCB (Maxwell) with the ability to manual read temps or voltages on the back of PCB: 980 strix and all gun metal Zotac. PNY also allows manual measurements on one of dual fan OC models with i2c support. All Asus strix have i2C advanced support. A few Zotac models support i2c. Most others (MSI/EVGA/Gigabyte) don't. Advanced i2C support on a PCB is helpful. http://i2c.info/i2c-bus-specification | |
| ID: 40648 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
https://www.gpugrid.net/forum_thread.php?id=3551 For the Titan X, excellent system cooling would be essential for long term crunching, given the high memory temps. I would go for direct air cooling on the back of one or possibly 2 cards, but if I had 3+ cards I would want a different setup. The DEVBOX's just use air cooling, with 2 large front case fans, but I suspect the memory still runs a bit hot. Just using liquid wouldn't be enough, unless it included back cooling. I guess a refrigerated thin-oil system would be ideal, but that would be DIY and Cha-Ching! Cooling 12GB appears to be a big issue and it's likely hindering boost and power consumption, but without the 12GB it wouldn't be a Titan, saying as it doesn't have good dp. Hopefully a GTX980Ti with 6GB will appear soon - perhaps 2688 cuda cores, akin to the original Titan, but 35 to 40% faster for here and <£800, if not <$700 would make it an attractive alternative to the Titan X. Recent reports point to a full GM200 980Ti with 6GB - June/July launch. | |
| ID: 40659 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
The easiest way to cool the memory on the back side would be small passive aluminum RAM coolers. They're obviously not as strong as full water cooling, but cost almost nothing and given some airflow could easily shave off 20 - 30°C. There's not enough space for this in tightly packed multi-GPU configurations, though. | |
| ID: 40661 | Rating: 0 | rate:
| |
|
You would think so, but I have a colleague who has bought four (4) 30 inch screens only to play flight simulator! | |
| ID: 40670 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
Cooling 12GB appears to be a big issue and it's likely hindering boost and power consumption, but without the 12GB it wouldn't be a Titan, saying as it doesn't have good dp. Hopefully a GTX980Ti with 6GB will appear soon - perhaps 2688 cuda cores, akin to the original Titan, but 35 to 40% faster for here and <£800, if not <$700 would make it an attractive alternative to the Titan X. That is very good news indeed. Perhaps I'll wait for that card then. 6GB is ten times more than a GPUGrid task needs so it's an overkill. Then 12GB would be ... complete waste of money. | |
| ID: 40672 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
|
As more data aggregates, I get more confused. | |
| ID: 40678 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
There may be a pattern: | |
| ID: 40679 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
There may be a pattern: 2% [4% Total] Hyper Threads usage for each ACEMD process. [2] physical cores for AVX DP @ ~60% Total CPU. (OS accounts 1%) GK107 exhibits this behavior: 98% core for NOELIA > GERARD 94%. (13773 atom) SDOERR_villinpubKc 87%. Powerful GPU's affected even greater. Comparing top two time: GERARD_FXCXCL12_LIG_11543841 --- (31843 Natoms) -Titan X (Win8.1) Time per step [1.616 ms.] 8.8% faster than [1.771 ms] GTX780ti (XP) GTX780ti (XP) output 91% of Titan X (Win8.1) for this particular unit. Titan X without WDDM tax lower's time per step and Total Runtime another 10%? GERARD_FXCXCL12_LIG_11543841 --- (31843 Natoms) [28,216.69/30,980.94] 9% Runtime difference Titan X (Win8.1) > 780ti (XP) Titan X possibly 20~% faster with (XP) at similar power consumption. Titan X core clocks are unknown (overclocked?) further complicating actual differences among (footprint) variables. | |
| ID: 40686 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Over the last couple of years the performance variation between task types has increased significantly. This has made it awkward to compare cards of different generation/even sub-generation. Task performances vary significantly because different tasks challenge the GPU in different ways, even exposing the limitations of more subtle design differences. | |
| ID: 40687 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
GERARD_FXCXCL12 update: | |
| ID: 40695 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
http://videocardz.com/55419/nvidia-geforce-gtx-980-ti-confirmed-to-feature-6gb-memory GM200-310 GPU will feature custom PCB cooling solutions. GM200-400 Titan X available cooling options are a water block or reference blower. As of now: unknown if GM200-310 GTX980Ti is a (24SMM) full die or 20-23 SMM cut down. | |
| ID: 41008 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
The 980Ti was inevitable and it's design predictable. | |
| ID: 41017 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
http://videocardz.com/55566/nvidia-geforce-gtx-980-ti-performance-benchmarks The GTX980ti launches in ~two weeks. (a new 7.5 CUDA toolkit will also be released) 980ti compute set is C.C 5.2 -- same as Titan X and 980/970/960. The GTX980ti consists of 2816CUDA (22SMM) with 176 Texture Mapping Units. ROPS are either 96 or 88 depending upon GM200 disablement process. Off topic, Pascal is supposed to introduce 3D memory and Unified memory (CPU can access it) and NVlink for faster GPU to CPU and GPU to GPU communications. These abilities will widen possible research boundaries, making large multi-protein complex modelling (and similar) more accurate and whole organelle modelling possible. Now the question is: when will 16nm Pascal/Volta be released? 12-18Months? Maxwell overclocking abilities are impressive compared to Kelper. Will 1500-1600+MHz clocks be possible on 16nm? | |
| ID: 41128 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Looks like NV added 128cores more than I thought they would, possibly suggesting better yields or architecture (no 3.5/4GB issues here, as promised). | |
| ID: 41193 | Rating: 0 | rate:
| |
|
Jozef J Send message Joined: 7 Jun 12 Posts: 112 Credit: 1,118,845,172 RAC: 0 Level Scientific publications | |
|
http://www.techpowerup.com/212981/asus-gigabyte-and-msi-geforce-gtx-980-ti-reference-graphics-cards-pictured.html#comments | |
| ID: 41209 | Rating: 0 | rate:
| |
|
Jozef J Send message Joined: 7 Jun 12 Posts: 112 Credit: 1,118,845,172 RAC: 0 Level Scientific publications | |
|
The second part: There is one very interesting and informative web page about this my card | |
| ID: 41210 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
http://anandtech.com/show/9306/the-nvidia-geforce-gtx-980-ti-review http://www.guru3d.com/articles-pages/nvidia-geforce-gtx-980-ti-review,1.html http://www.tomshardware.com/reviews/nvidia-geforce-gtx-980-ti,4164-8.html 980ti MSRP is 649usd. 980 MSRP 499$. Custom PCB (and reference PCB) Hybrid models for both Titan X and GTX980ti will manage GM200 temps (35-60C) during the summer computing ACEMD 24/7 unlike typical +80C core reference blower model. | |
| ID: 41219 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
|
http://anandtech.com/show/9306/the-nvidia-geforce-gtx-980-ti-review | |
| ID: 41222 | Rating: 0 | rate:
| |
|
Francois Normandin Send message Joined: 8 Mar 11 Posts: 71 Credit: 654,432,613 RAC: 0 Level Scientific publications | |
|
Over 1 million credit/day seem realistic. | |
| ID: 41225 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Estimated current Long run only Maxwell RAC per day (crunching 24/7) including OS variability factors: 1.1-1.4mil for [1] Titan X GM200/GM204/GM206 Price per core (current MSRP): -Titan X: 32.5cents (999$) GTX980ti offers Maxwell's best price/RAC ratio computing ACEMD. 980 and 970 also provides an excellent price/RAC. Possibly an App (update) improvement will help GM200/204 scaling to further increase RAC. | |
| ID: 41228 | Rating: 0 | rate:
| |
|
So anyone have one of the 980ti's on here yet? Was just able to order one today, should have it running by sunday. | |
| ID: 41262 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Should be >90% as fast as a GTX Titan X. | |
| ID: 41263 | Rating: 0 | rate:
| |
|
[CSF] Thomas H.V. DUPONT Send message Joined: 20 Jul 14 Posts: 732 Credit: 105,130,366 RAC: 275,493 Level Scientific publications | |
Look forward to seeing your runtimes. Yes, absolutely. Thanks in advance to 5pot for sharing ;) ____________ [CSF] Thomas H.V. Dupont Founder of the team CRUNCHERS SANS FRONTIERES 2.0 www.crunchersansfrontieres | |
| ID: 41272 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
Looks like it didn't turn up... | |
| ID: 41275 | Rating: 0 | rate:
| |
|
It did not. I should have read that next day air ships "next business day". Which could theoretically mean it will arrive on Monday or Tuesday. Either way, I'll have it up and running once it arrives. So at the absolute latest, expect results to be turning in by Wed. | |
| ID: 41276 | Rating: 0 | rate:
| |
|
The card is up and running, with a boost clock (from factory) @ 1315MHz. Not bad at all, considering the boost clock listed is 1190. Results will start reporting over-night, and temps are sitting at 60C w/ a 51% fan setting @ 1187mV. | |
| ID: 41280 | Rating: 0 | rate:
| |
|
localizer Send message Joined: 17 Apr 08 Posts: 113 Credit: 1,656,514,857 RAC: 0 Level Scientific publications | |
|
My EVGA 980Ti SC is up and running - initial impressions are quick and quite cool in my setup; time & returned results will tell more. | |
| ID: 41283 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
My EVGA 980Ti SC is up and running - initial impressions are quick and quite cool in my setup; time & returned results will tell more. I would like to thank all GPUGRID crunchers - who are healing the world one molecule at a time. I appreciate the incredible dedication of resources - offered freely and willingly to (BOINC) noble GPUGRID project. Has the GPUGRID Project ever had an inside cruncher appreciation event in it's history? Or any type of cruncher event? Team events occur outside of the project. What type of event can we have to celebrate the project's crunchers? The performance tab could offer new category types for such an event. The card is up and running, with a boost clock (from factory) @ 1315MHz. Not bad at all, considering the boost clock listed is 1190. Results will start reporting over-night, and temps are sitting at 60C w/ a 51% fan setting @ 1187mV. Thank you for reporting. GM200 at 60C pretty good on (air)? 25K GERALD Runtimes are similar to RZ fastest 980. If time permits: Could you comment on the task's core/MCU/BUS/power usage? Current GM200 comparisons: NOELIA_ETQ_unboun/NOELIA_ETQ_boun performance tab [8] Titan X builds -- 6 are 40 lane PCIe CPU's [5] x99 chipset -- [1] Dual socket Haswell Xeon -- [1] Z87/97 35W T series -- [1] Z87/97 K series. The LC system(s) temperature computing ACEMD: low 30's to mid 40's. GM200's ACEMD temps vary 32C-85C (Liquid vs. reference air). ACEMD on GM204 is stable at 1.5GHz. GM200 owner forums report >1400MHz(folding@home) and +1.5GHz for 3dmarks firestrike. GM200 optimal capability yet to be fully realized. (Once the projects scientists GERALD and NOElIA tasks are finalized - maybe an app update appears.) GM200 (WU utilization) is less than optimal. Current WDDM Titan X GERALD runtimes are as fast Petebe's XP 970. Linux and XP is clearly faster by >10% than WDDM. 2 tasks at a time on WDDM OS's = higher utilization. Total tasks crunched per day also rise by 10%* See ETA's "multiple WU" thread at number crunching. GM200 upgrade path is another year or two away. (PCI4.0/NVlink/HBM2 are a part of Pascal (Volta) technology advancement.) GM200 thermal energy (BTU output): 1 GM200 GPU (300W) at 24552 BTU/day > 1023 BTU/hr > 17.05 BTU/min > 0.2843 BTU/sec --- 3/4 GPU's (900-1200W) set-up 75-100K BTU/day --- Powerful dispersion for GM200's massive die is essential. Efficient disperse control assists in keeping thermal energy from destroying the PCB. +300W PCB's are aided by the advantages of liquid thermodynamics or a very powerful air cooled heatsink. Gigabyte 980ti cooler is rated for 600W. GM200's 6/12GB GDDR5 Controller accounts for 50+W. An example of adaptive cooling: EVGA's hybrid GM200/204 120mm rad (Pump mounted near PCB with GPU only LC - fan and a metal plate cool VRM/mem circuitry). I've sold (bartered) off spare parts (m2SSD/RAM/HDD) for savings towards the 980ti. Nearly garnered 5/8 of the 980ti MSRP. Having the older pieces paying for new purchases - certainly helps reduce current out of pocket expenses. I'm not sure if I want Galax's HoF or the 8+6pin EVGA Hydro copper or [2]8pin Zotac block. | |
| ID: 41284 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
Linux and XP is clearly faster by >10% than WDDM. This is likely to be higher with bigger cards. 2 tasks at a time on WDDM OS's = higher utilization. Total tasks crunched per day also rise by 10%* See ETA's "multiple WU" thread at number crunching. Likely to be higher with the GM200's, so long as you free up sufficient CPU resources. I would try 2 tasks at a time and then 3. If 3 better, then 4 (no CPU tasks). Would definitely use SWAN_SYNC=1 (and restart). Going by Localizer's returns -NOELIA_ETQunboundx1 tasks look like they are only 2 or 3% faster on a GTX980Ti than a GTX980, but SWAN_SYNC isn't on and who knows how much the CPU is being pushed? On my GTX970's these NOELIA_ETQunboundx1 tasks are struggling to push the cards hard enough to keep them interested (GPU0: power 20%, usage 83%, 41C, 405MHz [downclocked], GPU1 power 76%, usage 67%, 64C, 1266MHz). ____________ FAQ's HOW TO: - Opt out of Beta Tests - Ask for Help | |
| ID: 41285 | Rating: 0 | rate:
| |
|
Huh, I hadn't even realized swan_sync had to be started again. I remember it wasn't needed for awhile. I'll change that when I get back home. | |
| ID: 41286 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
My guess is that if someone used a Titan X or 980Ti on XP or Linux it would perform much better and on Vista-W10 if SWAN_SYNC=1 was used, no CPU tasks were running and 2 or more tasks were run at the same time the overall performance would be much better. I would even suggest that running 2 tasks on Linux/XP might be beneficial. | |
| ID: 41287 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Going by Localizer's returns -NOELIA_ETQunboundx1 tasks look like they are only 2 or 3% faster on a GTX980Ti than a GTX980, but SWAN_SYNC isn't on and who knows how much the CPU is being pushed? NOELIA_ETQunboundx (no SWAN_SYNC) GK107's show a 4% utilization drop (88/92%) with 2 CPU task vs. none. GM200/GM204 will see at least >4% if CPU has other WU's with or without SWAN. On GERALD's: a Quad CPU + GM204 will lose <5% GPU utilization with two CPU tasks. With 1 task = 3% while having 4 CPU WU causes a lose of 7%. (Haven't tested utility lose on current NOEILA with GM204/107.) I assume - with(out) SWAN - no matter how many PCIe3.0 lanes are active: any GPU's core/MCU/BUS ACEMD usage will still drop when the CPU has other tasks computing. On my GTX970's these NOELIA_ETQunboundx1 tasks are struggling to push the cards hard enough to keep them interested (GPU0: power 20%, usage 83%, 41C, 405MHz [downclocked], GPU1 power 76%, usage 67%, 64C, 1266MHz). This batch looks to be working the GPU's cache harder. Runtime theory: The 1/1 Titan X 24SMM vs. 22SMM 1/1. with 3072MB L2 cache affect runtimes ever so slightly. Will the 980ti truly be faster than the Titan X at ACEMD? A stalled cache can render Maxwell overclocks null and void. Currently: (10k/30K) runtime - My 750's 4/1 (4SMM/2048MB L2 cache) NOELIA_ETQunboundx output is 33% of the 980ti. . The 980ti is a (512/2816CUDA) larger GPU by 5.5x. 750 core amount is 18.1% the GTX980ti. From the look of it: the 980ti (10K) are twice GK104's runtimes at 16-28K. GTX980ti ETQunboundx runtimes are 8 to 9x better than my GK107 at (77K). | |
| ID: 41288 | Rating: 0 | rate:
| |
|
By the way, I thought it was SWAN_SYNC=0? Or did that change to 1? | |
| ID: 41289 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
It's no longer 'necessary' for a good performance, but in my experience it still speeds things up a few %. The 334 driver brought things back to normal re controlling the CUDA runtime to use a low-CPU mode without the performance dropping away (prior to that it was needed to get better performance and made more of a difference). On Windows it might just need to exist now, but on Linux I think it needs to be 1 (both used to be 0). | |
| ID: 41290 | Rating: 0 | rate:
| |
|
Enabled swan_sync, took another task off WCG, got 7.26 on Gerard. Over clock is a tad over 1400MHz now with a .12mV voltage increase. | |
| ID: 41298 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
That's around 9.5% of an improvement over your previous setup and not far off the performance of a Titan X (on the chart; 150% vs 156%), not that I know the setup that was used there (optimizations, CPU usage). | |
| ID: 41300 | Rating: 0 | rate:
| |
|
With swan sync on, Gerald was actually 81%. Memory default I'll have to look at when I get back home, and I don't remember noelia usage. | |
| ID: 41301 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
You should try to run 2 tasks at a time on the GTX980Ti to get some idea of what the gain is. I'm trying this now on two GTX970's and it looks promising, but these GM's are high maintenance; I have to use NVidia inspector to keep the clocks high. A look at hostid=137780 (win8.1) 970 computing two at a time reveals ~8WU per 24hr NOELIA_ETQunboundx. (2 tasks finish in 22k/sec) The 970's 2WUat gain up to 40% ETQunboundx daily improvement vs. 1WUat 970's. A Win7 GTX980ti daily ETQunboundx = 10.1WU (1WU per 2.36hr) >20% higher than (2WUat) 970. One ETQ task at a time GPU's: RZ's 980 output 9WU per day. (My 17SMM completes 9 per day or 1WU per 2.66Hr). 980ti supplies 27.3% more cores than a 980 - the 980ti present daily ETQ performance 10% higher than the fastest XP 980 and >15% WDDM 980's. (10-15% figures concern 1 WU at a time.) | |
| ID: 41302 | Rating: 0 | rate:
| |
|
Just to get back to you, the memory is at 3505MHz. | |
| ID: 41306 | Rating: 0 | rate:
| |
|
localizer Send message Joined: 17 Apr 08 Posts: 113 Credit: 1,656,514,857 RAC: 0 Level Scientific publications | |
|
Had a couple of days with the 980Ti now. In my setup it runs comfortably at 1400, any higher and I lose a few WUs. | |
| ID: 41307 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
the interesting tidbit for me was that the 980ti is doing noelia in around 10k seconds, with my older 680 rig doing them in 18k seconds. and now your returning in <9K: Run time 8,985.24 CPU time 8,834.44 https://www.gpugrid.net/result.php?resultid=14259463 I ran 2 NOELIA tasks at a time on my GTX970's to see what I could do. These are from the faster card: e3s32_e1s258f65-NOELIA_ETQunboundx2-1-2-RND7802_0 10992237 21,718.60 20,296.04 75,000.00 e5s76_e1s526f70-NOELIA_ETQunboundx2-0-2-RND6354_0 10992080 21,638.48 20,227.95 75,000.00 My fastest NOELIA by itself: e1s451_1-NOELIA_ETQunboundx1-0-2-RND8377_0 10984428 13,889.76 13,889.76 75,000.00 Suggests a 28% overall improvement on a little GTX970. Localizer, 75% usage on Noelia WUs & 79-80% usage on Gerard WUs. Plenty of room there for 2 tasks :) How To create and use an app_config.xml file in Windows ____________ FAQ's HOW TO: - Opt out of Beta Tests - Ask for Help | |
| ID: 41308 | Rating: 0 | rate:
| |
|
@localizer. I'm surprised you're losing WUs above 1400. I'm sitting at over 1450 now, and still think I may be able to push higher. | |
| ID: 41310 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
|
5pot, your GPU is under 60C whereas localizer's is reaching 71C. | |
| ID: 41313 | Rating: 0 | rate:
| |
|
Well, I tried to hit 1500, and walked away for the night. | |
| ID: 41318 | Rating: 0 | rate:
| |
|
skgiven Volunteer moderator Volunteer tester Send message Joined: 23 Apr 09 Posts: 3968 Credit: 1,995,359,260 RAC: 0 Level Scientific publications | |
E: unless there's a way I can make it stop getting tasks through the website I suppose. You should be able to do that by editing your preferences and deselecting,
the ACEMD GPU apps [If no work for selected applications is available, accept work from other applications?] Use Graphics Processing Unit (GPU) if available.
| |
| ID: 41320 | Rating: 0 | rate:
| |
|
localizer Send message Joined: 17 Apr 08 Posts: 113 Credit: 1,656,514,857 RAC: 0 Level Scientific publications | |
|
........... my 980Ti is in a SFF case and is a reference card. | |
| ID: 41321 | Rating: 0 | rate:
| |
|
[CSF] Thomas H.V. DUPONT Send message Joined: 20 Jul 14 Posts: 732 Credit: 105,130,366 RAC: 275,493 Level Scientific publications | |
the interesting tidbit for me was that the 980ti is doing noelia in around 10k seconds, with my older 680 rig doing them in 18k seconds. https://twitter.com/TEAM_CSF/status/609620024215633920 ____________ [CSF] Thomas H.V. Dupont Founder of the team CRUNCHERS SANS FRONTIERES 2.0 www.crunchersansfrontieres | |
| ID: 41322 | Rating: 0 | rate:
| |
E: unless there's a way I can make it stop getting tasks through the website I suppose. Thank you for reminding me of this, changed it when you posted. I've got it clocked down to 1375 for the 2 weeks I'll be away. Want to make sure I don't lose that much crunching time for an OC. @Localizer, these cards can do really well. Good luck with the fine tuning of your card. @Dupont, thanks for the shout out. :) When I get back, I'll try and hit 1500. But I'm beginning to think I'll need to overvolt a little more than I would like to run it permentantly at. But it's always fun to see where the max is. | |
| ID: 41358 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
Running 1 WU I don't expect the 980Ti to be 37.5% faster than a GTX980 NOELIA_46 (467x) update: -single 980ti WU (2.903ms) per step performances (+18.3 to 30%) capable a (3.553ms) GTX980. -980ti per step efficiency (+30 to 50%) the routine 970 (4.168 ms). -GTX750 10.878ms per step (-73.3%) a 980ti. -Surprisingly: GM107 have nearly the same NOELIA_46 runtimes as cut GK104's. So, it would better to compare the 980Ti against the well established performances of the GTX980. 56k/atom NOELIA_46 WU realizing GM200's (and GM107/206/204) superior ACEMD performance. Noelia per WU utilization tends to be higher than GERALD 32K/atom design. GM200's single WUat throughout can steadily be +30% the fastest GM204's at ACEMD. When configured in peak compute conditions - a 50% increase over GM204 is viable. If the many ACEMD environment factors that can increase (Maxwell) WU runtime are active - a 50 to 70% output lose incurs compared to 2WUat. (I've purposely found the negative limit for my 970 at 1.5GHz. Next up: Achieving top performance. ACEMD is sensitive to slowdown factors.) skgiven recently outlined some ACEMD performance factors: That is a bit faster, albeit only ~2.5%. This is because the latest apps are quite good at utilizing the GPU without much CPU reliance and you have 4 real cores with 4 true threads. On CPU's with HT the difference tends to be higher. For efficiency sake: PCIe x8 required for any Maxwell - big or small. Single GPU or multi - ACEMD is influenced and very sensitive to serial links and <3GHz CPU's. An under clocked CPU and MB whose PCIe lanes are saturated - reckons runtimes. Demanding BUS tasks on x4 are driven away from optional performance. ACEMD is one of the BOINC tasks affected 20% on x4 compared to x8/16. Primegrid's N17 Genefer is another. PCIe NVMe/SATAe SSD can hamper Multi GPU's compute runtimes. (z97 chipset) BOINC USB stick and HDD storage factors show zero inference with the GPU unlike a PCIe SSD. Skylake CPU's will improve upon transfers. FYI: Maxwell BIOS tweaker program interprets clocks involved with the GPU. For example: the GM107 L2 cache clock -26-39MHz the GPC. GM204 or GM200 stock vBIOS sometimes show a 150-200MHz difference between the four boost/clock states XBAR/SYS/GPC/L2C. AMD's hybrid cooled flagship (Fury X) is available today - will GM200 MSRP drop in a couple of weeks? http://wccftech.com/amd-radeon-r9-fury-launch-reviews-roundup/ Toms hardware: Whereas GM200 measures 601mm², Fiji is almost as large at 596mm². AMD crams a claimed 8.9 billion transistors into that space, and then mounts the chip on a 1011mm² silicon interposer, flanking it with four stacks of High Bandwidth Memory. Thermal imagery: http://www.tomshardware.com/reviews/amd-radeon-r9-fury-x,4196-8.html SP/DP ratio is 1/16 - similar as Tonga GCN1.2 cores rather than GCN1.1 gaming Hawaii 1/8 (Hawaii Firepro series is 1/2 SP/DP). If a professional Fiji arch is released: FP64 performance might be 1/2 or 1/4 ratio or 1/8 or stay at 1/16. | |
| ID: 41395 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
http://www.guru3d.com/articles_pages/zotac_geforce_gtx_980_ti_amp_extreme_review,8.html GM200 (MSI/ASUS/EVGA/ZOTAC/GALAX/INNo/Giga) custom PCB released as a couple were reviewed. Overclocked Ti's surpass reference Titan X and Fury X performance. Custom PCB GM200 have 50$ or more premium asking price over ref. The 10 phase (8+2) - GM200 3 slot heavy set AMP extreme Zotac (320W OP) 'so far' has the highest out of box (1203 TDP base/1355boost) clocks. Rated higher than a 18 phase HoF. The not yet released 17 phase (14+3) Kingpin edition is rumored to be (52MHz) 4 bins better at stock TDP core/boost. 14+3 Classified EVGA's are rated 1 bin less at stock TDP base clock than Zotac's. Gigabyte G1 has shown to be an overclocking beast with it's 600W heatsink and 10 (8+2) phase custom PCB. The ref 6+2 phase PCB limits WC GM200 if lucky 1500 24/7 before VRM start breaking down. GM200 LC or air cooled Custom PCB's >1600MHz is the forefront of 24/7 overclocks. (At these speeds: overclock's will either fail quickly or last to pass depending on the code. Precision testing mandatory for error free long-term compute) There is a 100MHz difference for my 970 between three BOINC projects: 1.5GHz for ACEMD to 1.6GHz for Primegrid's CUDA PPSsieve. POEM's OpenCL is in the middle. Zotac 980ti EX seems not to include (3) 980/970 AMP 13 phase (8+3+2) omega/extreme features: the L2N BIOS switch - manual voltage read out points - Texas Instruments MSP430 USB microcontroller that can be custom programmed. EVGA hybrid/Inno black/ZOTAC articstorm with a (full water block and 3 fans) are the standard 6+2 phase ref PCB with VRM heatsink. Buying a ref 980ti and EK water block costs a touch more than readymade GM200 LC. All these choices are making for decision zap. My newly purchased Z97 MSI MPOWER MB with 3 x16PCIe3.0 slots is waiting for an upgrade. The furthest PCIe slot from CPU true 8lane circuitry - not a 4 lane. (underside of MB shows 8 as does the power slot pins in a 16pin physical slot.) So with 3 GPU's it should be 8x/8x/8x MB. The ti on x8 slot should be enough. A 980ti/970/750 MB around 1.7mil RAC/day at 500W (GPU). If I replace the 750 with a 980 - RAC 2.2mil/day at 650W GPU and <750W system total. Is a platinum 1000W PSU with a 85amp 12V single rail enough to drive a 980ti/980/970 24/7/365 who are all 1.5GHz? Or 1200W/>100amp rail PSU? Consumption/RAC ratio for all Maxwell's are much better than Kelper's. My 970 is currently at 125W for NOELIA_ETQ and 140W for GERALD with <73% core usage. The 970 pulled 175W on ~83% core usage NOELIA_S4 during April. 212W is highest I've seen (AIDA64 Integer) benchmark and SiSoftware. For DP code: 52 total DP cores = 130W. An overclocked GM200/204/206 will operate 30% above "rated" TDP if a heatsink can handle the extra heat. GM200 overclocks can add an extra <50% performance vs. reference speeds dependent upon application MHz scaling. A side note: GTX950(ti) GM206 is supposedly going to be released soon: 768 or 896 cores. (ROP/memory sub-system is unknown) If 950(ti) cache and ROPS are 960's size: a reasonably fast GPU. As 750(ti) before it - the 950(ti) a choice economical system GPU for ACEMD compute. in my opinion the best nvidia GFC 980 based, while published as custom design pcb and cooling.. Indeed - although some were experiencing problematic voltage settings that limited overclocks. Zotac's (broken) firestorm program supposedly designed to work the USB MC. Multi GPU's on MB cause firestorm to stop working. (RIVA based overclocked programs also have an issue with GM204 AMP omega/extreme voltage sliders while NV inspector works fine.) I only recommend NV inspector for overclocks. NVinsp footprint is much smaller than MSI or EVGA. Zotac created 4000 total omega/extreme: 1000 omega 970/1000 omega 980/1000 extreme 970/1000 extreme 980. Zotac's Customer service was informative and helpful towards me - providing detailed GPU dynamics. e.g. life expectancy algorithm absolute values - assuring ~1.6GHz for years to come. So far stable OC's held three months non-stop BOINC projects. | |
| ID: 41472 | Rating: 0 | rate:
| |
|
That was some good info. I personally always have a hard time swallowing how expensive sone of those boards get. Those they're for benching, but still. | |
| ID: 41486 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Here's what one of the world known OCer's (Has a GPU in his name) says about Maxwell: Honestly speaking, I think most end users don't even realize how maxwell gpus are voltage capped at ambient type cooling. I can tell by many of the comments at OC.net, elsewhere, and also here in these card XOC bios threads. Especially compared to kepler. KP 780ti scaled great on voltage with air/water temps. Basically, more voltage = more clocks no matter what temperature. | |
| ID: 41493 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Posted 30th of March: GERARD_FXCXCL12 update: Since GM200 March release - numerous GM200's attached to GPUGRID. Currently Petebe's GERARD_FXCXCL12 (newly released batches) 22k/sec 980ti runtime(s) 13.3% faster than XP's best 980's. The 980ti (1.289ms) per step 12.9% quicker (1.462ms). XP OS light speed systems are leading the pack as always. (Maxwell upgrade) from Fermi and Kelper on XP or Linux garner significant performance benefits. 2WU at a time Maxwell GPU's WDDM system(s) almost make up the performance gap vs. XP/Linux one WU at a time. Zoltan's test 980ti has the fastest GERALD_FXCXCL12 WU ever completed. https://www.gpugrid.net/forum_thread.php?id=4100&nowrap=true#41570 (1.114ms. per step) 23% faster than (RZ) 980 XP system. The host that RZ tested the 980ti with also had a 970 completing GERALD's in 30.5k/sec. This is the fastest 970 GERALD single WUat ever recorded. Time per step was 1.745ms. | |
| ID: 41576 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 386 Level Scientific publications | |
... The host that RZ tested the 980ti with also had a 970 completing GERALD's in 30.5k/sec. This is the fastest 970 GERALD single WUat ever recorded. Time per step was 1.745ms. That GTX 970 is an EVGA GeForce GTX 970 SSC ACX 2.0+, and I haven't pushed it more than the factory overclock. | |
| ID: 41580 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
https://xdevs.com/guide/maxwell_big_oc/ | |
| ID: 41586 | Rating: 0 | rate:
| |
{kind=link}
Message boards : Graphics cards (GPUs) : Big Maxwell GM2*0