Message boards : Graphics cards (GPUs) : Ampere 10496 & 8704 & 5888 fp32 cores!
| Author | Message |
|---|---|
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Incredible amount of compute power compared to Turing! | |
| ID: 55227 | Rating: 0 | rate:
| |
|
Keith Myers  Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
I didn't see any publication of the actual memory clocks. Just the bandwidths. Will wait and see what the actual specs and test results are once the actual cards are in the hands of testers. Just because the cards will be great pixel pushers for ray-tracing games doesn't mean they will produce the commensurate compute improvements. | |
| ID: 55229 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Integer32 performamce same as fp32 and int32 Turing 1:1? | |
| ID: 55230 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
The idea of going to "Wrapper" with ACEMD3 was to enable easier development of apps for new CUDA / Architectural releases. Interested to see how easy this path will be....The holdup may be Nvidia and how fast they release the next CUDA Toolkit. | |
| ID: 55231 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
The trick will be to use all the new hardware in the best parallelization of the current and future searches. | |
| ID: 55232 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
What concerns me: will Turing quality control issues crop up on Ampere? | |
| ID: 55237 | Rating: 0 | rate:
| |
 Retvari Zoltan Retvari ZoltanSend message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
|
I expect that the CUDA cores could be used for crunching will be only the half of that stated in the name of this thread. card cores performance
RTX 2080Ti 4352 100.0%
RTX 3090 10496 5248 120.6%
RTX 3080 8704 4352 100.0%
RTX 3070 5888 2944 67.6% Perhaps a bit (say 10%) more (taking other factors in consideration). | |
| ID: 55238 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
I think the CUDa core counts might be a bit of marketing magic. They claimed in the article that the Ampere cores can do 2 operations per clock, which is effectively doubling the work done, on a single physical core. We’ll see how it shakes out for compute work. | |
| ID: 55239 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
I expect that the CUDA cores could be used for crunching will be only the half of that stated in the name of this thread. I think you will be correct also. I saw the published CUDA core counts and thought marketing nonsense. Unless they fundamentally changed the architecture design, I think they just doubled the physical core counts by the new 2 operands per cycle PAM memory operations. | |
| ID: 55242 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
Did some more reading and I think I got a better grasp on the whole CUDA core count issue and relative performance. | |
| ID: 55243 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
Did some more reading and I think I got a better grasp on the whole CUDA core count issue and relative performance. Thanks for the analysis. Will have to wait and see how they assign SMs to each GTX model to gauge the performance increase for each model. Nvidia will not give their technology away, so I suspect you are right in saying it will only be a generational performance increase for us. | |
| ID: 55246 | Rating: 0 | rate:
| |
|
Well, I'm optimistic :) | |
| ID: 55279 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
Hopefully, the Amperes will be showing up on the Passmark GPU Direct Compute ratings soon. | |
| ID: 55281 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
https://www.tomshardware.com/features/nvidia-ampere-architecture-deep-dive | |
| ID: 55292 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
https://www.tomshardware.com/news/nvidia-geforce-rtx-3080-review | |
| ID: 55302 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
So far all the cards are power limited. Almost no overclocking potential. Maybe 2-3%. Doubt the 3090 cards will be any different. | |
| ID: 55304 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
So far all the cards are power limited. Almost no overclocking potential. Maybe 2-3%. Doubt the 3090 cards will be any different. You are right even with enough power the oc wall is 2GHz - many forums reporting Ampere 3080 crashing at 2GHz. Ampere release eery similar to Turing. Remember when early model 2080 and 2080ti were glitching out at stock clocks? Ampere improved founders cooling didnt help. Might be memory related due to new technology. And/or quality control with the massive dies. 12nm Die density on Turing TU102 25m transistors per mm. 8nm TA102 has 45m per mm. 7nm and 5nm are more dense. Finding a 3080 another story with limited availability. This is so bad Nvidia released a statement about availability. RTX3090 reviews published have oced clocks power consumption at 450W with a 480W power limit. 360W at out the box clocks. Big power increase for little performance gain. (2) 2080TI cards had 3 8 pin power connectors: the msi lighting and galax. Now all 3090 and most 3080 have (3) 8 pins or the new 12 pin on founders. | |
| ID: 55351 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Until the compute apps get recompiled for CUDA 11.1 and the new PTX library, none are going to show the potential from using the dormant extra FP32 pipeline in the architecture. | |
| ID: 55354 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
https://www.techpowerup.com/272591/rtx-3080-crash-to-desktop-problems-likely-connected-to-aib-designed-capacitor-choice | |
| ID: 55366 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
https://www.techpowerup.com/272591/rtx-3080-crash-to-desktop-problems-likely-connected-to-aib-designed-capacitor-choice Nvidia has released driver 456.55 to fix the issue. (driver appears to lower the boost to prevent the crashes during games) https://videocardz.com/newz/nvidia-geforce-rtx-3080-owners-report-fewer-crashes-after-updating-drivers ASUS and MSI have modified their designs to fix the crashes by implementing different capacitor configuration. https://videocardz.com/newz/asus-also-caught-modifying-geforce-rtx-3080-tuf-and-rog-strix-pcb-designs and https://videocardz.com/newz/msi-quietly-changes-geforce-rtx-3080-gaming-x-trio-design-amid-stability-concerns Hopefully just a minor speed bump in the release of the new Ampere Architecture. Plain sailing from here? | |
| ID: 55371 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
Plain sailing from here? No, not at all. No compatible apps yet. | |
| ID: 55372 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
Plain sailing from here? Based on past Architectural changes and app upgrades to match have taken 6 months or more for the new app. First Pascal GPU released May 2016, Gpugrid Pascal compatible app released November 2016. First Turing GPU released September 2018, Gpugrid Turing compatible app released October 2019. (Working from memory here, so please correct if the timeline is not right.) However, the change to Wrapper introduced on the Turing app upgrade, may shorten the app development cycle. | |
| ID: 55373 | Rating: 0 | rate:
| |
|
Toni Volunteer moderator Project administrator Project developer Project tester Project scientist Send message Joined: 9 Dec 08 Posts: 1006 Credit: 5,068,599 RAC: 0 Level Scientific publications | |
|
We don't have access to any card yet. | |
| ID: 55374 | Rating: 0 | rate:
| |
|
bozz4science Send message Joined: 22 May 20 Posts: 109 Credit: 68,936,176 RAC: 0 Level Scientific publications | |
|
Don't know if this has a lot of relevance for those of you currently considering to purchase or already having bought a RTX 30xx series card, but over at F@H they have recently been rolling out CUDA support on their GPU cores and were able to drastically increase the average speed of NVIDIA cards. | |
| ID: 55378 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
We don't have access to any card yet. don't think you really need a physical card to make the new app. just download the latest CUDA toolkit, and recompile the app with CUDA 11.1 instead of 10. when I was compiling some apps for SETI, I did the compiling on a virtual machine that didn't even have a GPU. as long as you set the environment variables and point to the right CUDA libraries, you shouldn't have any trouble. you really can do it on whatever system you used before. just make sure you add the gencode variables sm_80 and sm_86 to your makefile so that the new cards will work. so like this: -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_80,code=compute_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_86,code=compute_86 also give a look through the documentation for the CUDA 11.1 toolkit. https://docs.nvidia.com/cuda/index.html https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html take note this quote: 1.4.1.6. Improved FP32 throughput just make it a beta release, so those with an Ampere card can test it for you. ____________  | |
| ID: 55382 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
Don't know if this has a lot of relevance for those of you currently considering to purchase or already having bought a RTX 30xx series card, but over at F@H they have recently been rolling out CUDA support on their GPU cores and were able to drastically increase the average speed of NVIDIA cards. i think we might see a bigger uplift in performance actually. it seems those tests might be seeing speedups from increased memory capacity and bandwidth, combined with the core speed. I think the 3080 is *only* 10-15% ahead of the 2080ti because of memory config being limited to only 10GB of memory one thing that stands out to me, is that their benchmarks show the Tesla V100 16GB as being significantly faster than a 2080ti, but comparing empirical data from users with that GPU show it to actually be slower than the 2080ti at GPUGRID. this leaves me to theorize that GPUGRID doesnt utilize the memory system as much, and instead relies mostly on core power. this is further supported by my own testing where not only is GPU VRAM minimally used (less than 1GB), but increasing the memory speed makes almost no change to crunching times. if we can get a new app compiled for 11.1 to support the CC 8.6 cards, we may very well see a large improvement to the processing times since comparing the core power alone, the 3080 should be much stronger. ____________ | |
| ID: 55383 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
Don't know if this has a lot of relevance for those of you currently considering to purchase or already having bought a RTX 30xx series card, but over at F@H they have recently been rolling out CUDA support on their GPU cores and were able to drastically increase the average speed of NVIDIA cards.That's great news! They ran an analysis on the efficiency gain of the cards produced by the CUDA support and included in one of their analysis an RTX 3080.That's the down to earth data of their real world performance I've been waiting for. I can't post pictures here, so just take a look at the third graph posted on this site.I can, but it's a bit large: (sorry for that, I've linked the original picture, at least the important parts are on the left) 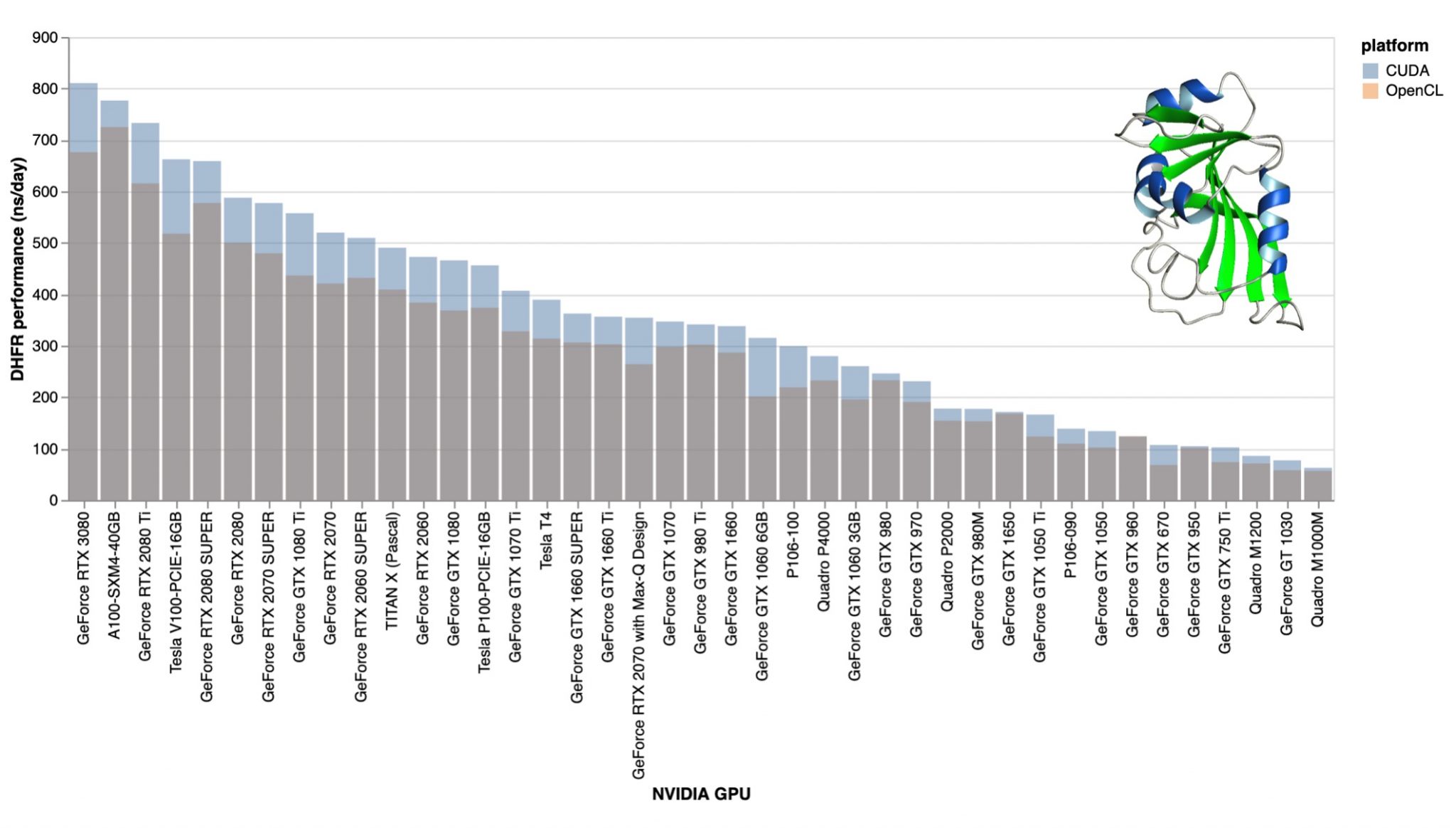 From what I can tell, the RTX 3080 achieves an improvement of 10-15% over a RTX 2080 Ti in this one particular GPU task they benchmarked the cards to. This might be interesting for benchmarking the performance here as well. Thought this might be of interest to some of you.That's the performance improvement I've expected. This 10-15% performance improvement (3080 vs 2080Ti) confirms my expectations about the 1:2 ratio of the usable vs advertised number of CUDA cores of the Ampere architecture. This is actually a misunderstanding, as the number of the CUDA cores are: RTX 3090 5248
RTX 3080 4352
RTX 3070 2944 but every CUDA core has two FP32 units in the Ampere architecture. Actually the INT32 part (existing in previous generations too) of the CUDA cores has been extended to be able to handle FP32 calculations. It seems that these "extra" FP32 units can't be utilized by the scientific applications I'm interested in. | |
| ID: 55384 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
but every CUDA core has two FP32 units in the Ampere architecture. Actually the INT32 part (existing in previous generations too) of the CUDA cores has been extended to be able to handle FP32 calculations. It seems that these "extra" FP32 units can't be utilized by the scientific applications I'm interested in. this is something we can't know until GPUGRID recompiles the app for sm_86 with CUDA 11.1. it will also depend on what kinds of operations GPUGRID is doing. if they are mostly INT, then maybe not much improvement, but if they are FP32 heavy, we can expect to see a big improvement. it's just something that we need to wait for the app for. as I mentioned in my previous posts, you can't rely on that benchmark very strongly. there are performance inconsistencies already between what it shows and what you can see here at GPUGRID (specifically as it relates to the performance between the V100 and the 2080ti) ____________ | |
| ID: 55386 | Rating: 0 | rate:
| |
|
bozz4science Send message Joined: 22 May 20 Posts: 109 Credit: 68,936,176 RAC: 0 Level Scientific publications | |
|
Just meant this as a pointer. Don't know what data they included in their analysis in the sense of how many GPUs were flowing in this data aggregation. Honestly, I am in way over my head with all this technical talk about GPU application porting, wrappers, code recompiling, CUDA libraries etc., even though I am trying to read up on it online as much as I can to get more proficient with those terms. | |
| ID: 55388 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
this is something we can't know until GPUGRID recompiles the app for sm_86 with CUDA 11.1.That's why I started that sentence by "It seems..." it will also depend on what kinds of operations GPUGRID is doing. if they are mostly INT, then maybe not much improvement, but if they are FP32 heavy, we can expect to see a big improvement.It's the latter (FP32 heavy). However it's not the type of the data processed that decides if it can be processed simultaneously by two FP32 units within the same CUDA core, but the relation of the input-output data of that process. This relation is more complex than what I can comprehend (as of yet). it's just something that we need to wait for the app for. as I mentioned in my previous posts, you can't rely on that benchmark very strongly.The Folding@home app and the GPUGrid app are very similar regarding the data they process and the way they process it. Therefore I think this benchmark is the most accurate estimation we can have for now regarding the performance of the next GPUGrid app on Ampere cards. In other words: it would be a miracle if these science apps could be optimized to utilize all of the extra FP32 units. there are performance inconsistencies already between what it shows and what you can see here at GPUGRID (specifically as it relates to the performance between the V100 and the 2080ti)The largest "inconsistency" is that the RTX 3080 should have ~1500ns/day performance if the 8704 FP32 units could be utilized by the present FAH core22 v0.0.13 app. I assume that the RTX 3080 cards run nearly at their power limit already. Processing data on the extra FP32 units would take extra energy; however the data flow would be closer to optimal in this case, so it would lower the energy consumption at the same time. The ratio of these decide the actual performance gain of an optimized app, but -- based on my previous experience -- an FP32 operation is more energy hungry, than loading/storing the result. So, as being optimistic on that topic I expect another 10-15% performance boost at best from an Ampere-optimized app. | |
| ID: 55390 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
was the F@h app compiled with SM_86? I couldn't find that info. as referenced in my previous comment from the nvidia documentation, that might be needed to get the full benefit from the double FP32 throughput. | |
| ID: 55391 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
Toni, what about that suggestion of a "blind compile" for a beta app? Maybe the gambling pays off and it works right away or after minimal debugging? | |
| ID: 55395 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
I think the existing app source code can just be recompiled with the new genarch parameters to get the app working like it already does with previous generations. | |
| ID: 55396 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
was the F@h app compiled with SM_86? I couldn't find that info. as referenced in my previous comment from the nvidia documentation, that might be needed to get the full benefit from the double FP32 throughput. What I can see of the finished PPSieve work done by the 3080, the app is still the same one introduced in 2019. So well before the release of CUDA 11.1 or the Ampere architecture. I have no idea why it can run with the older application. | |
| ID: 55410 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
I have no idea why it can run with the older application. If the app is coded "high level enough" I could see this work out. If nothing hardware or generation specific is targeted, all you do is to tell the GPU "Go forth and multiply (this and that data)!". MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 55411 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
I guess so. They must not have encoded a minimum or maximum level that can be used. Not looking for some specific bounds like the app here does and is currently finding the Ampere cards out of range. | |
| ID: 55412 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 399 Credit: 13,058,814,882 RAC: 3,202,157 Level Scientific publications | |
|
At 320 Watts the PCIe cables and connectors will melt. I make my own PSU cables with a thicker gauge wire but those chintzy plastic PCIe connectors can't handle the heat. If you smell burnt electrical insulation or plastic that's the first place to check. | |
| ID: 55420 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
A standard 8 pin PCIE cable can provide 150W. All the cards have either two or three 8 pin connectors which provide 300 or 450 watts PLUS the 75 watts from the PCIE slot. The founders edition cards have that new 12 pin connector which is just a duplicate capacity of two 8 pin connectors. Only six wires have 12V on them, the rest are grounds. | |
| ID: 55423 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 566 Credit: 6,149,877,024 RAC: 10,511,052 Level Scientific publications | |
|
Pulling the blanket from the link in this eXaPower post... | |
| ID: 55424 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
At 320 Watts the PCIe cables and connectors will melt. Have you checked the launch reviews and for that? And asked Google about forum posts from affected users? Tip: don't spend too much time searching. MrS ____________ Scanning for our furry friends since Jan 2002 | |
| ID: 55425 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
I arrived to this other interesting article about the new Nvidia 12 pin power connector.According to that paper, it has 80 µm tin plated high copper alloy terminals. Seriously, tin plated? It's not better than the present PCIe power connectors, it's just smaller. The SATA power connector has 15 gold plated pins: 3x +3.3V 3x GND 3x +5V 3x GND 3x +12V It has to deliver typically under 1A on each rails. (yes, it's distributed between the 3 terminals that rail has). Now the "revolutionary" 12-pin connector has to deliver 600 Watts (600W/12V) 50 Ampers on the 6 12V terminals, that's 8,33 Ampers on each terminal. If I take the typical load of 300W, it still has to deliver 4.17 Ampers on each tin plated terminal. Now, tin has 12 times higher contact resistance than gold: (note that the coordinates are logarithmic) 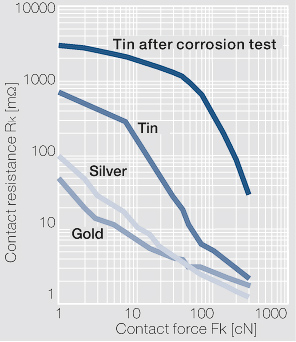 12 times higher contact resistance * 12 times higher current = 1728 times higher power converted to heat (compared to the SATA power connector) After a year of crunching 24/7, these connectors will burn like the good old PCIe power connectors did. | |
| ID: 55426 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
They carry a higher power rating because the base wiring spec is that of a higher gauge than the old cables. | |
| ID: 55427 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Yes, the new 12 pin connector is using 16 ga. wire which reduces the circuit resistance and has higher ampacity. The main thing to avoid is heating either the wire or the pins up as that can cause a runaway thermal condition which just increases the contact resistance which increases the heating and it just keeps building until failure. | |
| ID: 55428 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 566 Credit: 6,149,877,024 RAC: 10,511,052 Level Scientific publications | |
| ID: 55429 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 399 Credit: 13,058,814,882 RAC: 3,202,157 Level Scientific publications | |
|
I've gone through hundreds of GPUs in the 20 years I've been doing this and I've had a fair number of PCIe cables burn up at both the PSU end and the GPU end. The biggest problem is due to the wimpy crimps. Sometimes you can use an extraction tool and remove the terminal pin from the plastic connector and the terminal pin is just flopping around on the wire. Heats up like Keith described and the plastic melts. I found examples that I hadn't thrown in the trash yet. I'll photograph them and post later. | |
| ID: 55430 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
I got the AX1200s back when I thought it was a good idea to run 4 GPUs on a single motherboard. I now use only one or two and they must be on 16x 3.0 sockets. I believe PSUs are most efficient at 80% load so I'm under loading them now but I use what I have. I run upwards of 10 GPUs on the same board. no problems if you know what you're doing and plan it out correctly. 4 is a cakewalk. the biggest thing to be aware is that if you are using 3 or more high power GPUs on the same board, and you are getting power to them all from the motherboard, to make sure the motherboard has a dedicated power connection for the PCIe power. that's how you burn out the 24-pin 12v lines if you dont have that or dont plug it in. according to my PCIe bandwidth testing, GPUGRID (at current time) performs best on a PCIe 3.0 x8 or larger link. x16 isn't absolutely necessary. There's zero slowdown going from x16 to x8 on gen3. my previous 10-GPU (10x RTX 2070 pic: https://i.imgur.com/7AFwtEH.jpg?1) system ran on a board with 10x PCIe 3.0 x8 links (Supermicro X9DRX+-F) I ran this system for well over a year 24/7 mostly on SETI and moved to GPUGRID after it shut down. not a melted connector in sight. it was even getting slot power to each GPU from the motherboard (with the help of some power connections added via risers). x8 lanes to each GPU. this system ran on a Corsair 1000W PSU which powered the motherboard/CPUs, and 2x 1200W HP server PSUs providing all of the power connections to the GPUs (each PSU powering 5x GPUs). this system has since been converted to a 5x 2080ti system on an AMD epyc platform with CPU PCIe lanes to every slot. four(4) x16 slots, three(3) x8 slots). and every slot can be bifucated to x4 or x8. i'll probably expand it to 7x RTX 2080ti and leave it there (until I decide to update to 3080 or 3070 cards) I have another system (currently offline, pics: https://imgur.com/a/ZEQWSlw) with 7x RTX 2080, running at 200W each. all from a single EVGA 1600W PSU. it was running for months before I turned it off for some renovations in the room where the computer was running. again no melted connectors. even using single pigtail leads leads to each GPU (8-pin + 6-pin single cable). this is on an old X79 board with only 40 CPU based PCIe lanes, but the board uses several PCIe PLX switches to kinda sorta give more lanes. it works with minimal slowdown. ASUS P9X79E-WS mb. my 3rd system is currently 7x RTX 2070 (pic: https://i.imgur.com/136DaqP.jpg), again on the same AMD Epyc platform (AsrockRack EPYCD8 mb) as the 5x 2080ti system, but here all 7 slots filled. these particular RTX 2070 cards run a single 8-pin power plug, with the cards limited to 150W. 3x GPUs powered by the 1200W PCP&C PSU, and 4x GPUs powered from a 1200W HP server PSU I'm actually going to add an 8th card to this system by breaking one of the x16 slots to x8x8 and put two cards in one slot. I don't expect any issues. i have an x8x8 bifurcation riser on the way and the board fully supports slot bifurcation. if you plan it right, it works. this is much more energy efficient and simpler to manage not having 10 separate systems each with their own PSU(s) and CPU/mem sucking up power. you could go the USB riser "mining" route if GPUGRID wasnt so reliant on PCIe bandwidth. but "c’est la vie", and the wiring is cleaner with the ribbon cables anyway ;) ____________ | |
| ID: 55433 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Still using Corsair AX1200 power supplies running 3 gpus on two hosts. It is a good supply. | |
| ID: 55434 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Never had burnt 8 pin or 6 pin but always mechanical stuff die. Pumps or fans plus the GPU die. Like I said I had 4 Turing go cold out of 6. Overclocking the core shouldn't kill it all. Other generations didnt bed so easy. | |
| ID: 55435 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
I have had only one gpu electrical death in probably 30 cards or so in ten years. But the pumps in the hybrid gpus die fairly regularly. | |
| ID: 55436 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
https://www.phoronix.com/scan.php?page=article&item=nvidia-rtx3080-compute&num=1 | |
| ID: 55548 | Rating: 0 | rate:
| |
|
rod4x4 Send message Joined: 4 Aug 14 Posts: 266 Credit: 2,219,935,054 RAC: 0 Level Scientific publications | |
https://www.phoronix.com/scan.php?page=article&item=nvidia-rtx3080-compute&num=1 Plenty of good information on the above links. The graph that really stood out for me was this (courtesy of Phoronix): https://openbenchmarking.org/embed.php?i=2010061-PTS-GPUCOMPU18&sha=d2fb7b5c9b53&p=2 It shows if you pump plenty of power into a gpu, you get results, but at the expense of efficiency. The graph highlights that the rtx3080 card is not very efficient. Lets hope we see more efficient cards from Ampere in the coming months. | |
| ID: 55549 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Yes, not very efficient at all. On Windows at least with the standard gpu control utilities you can shove the power usage down and cut the boost clocks and save some power. | |
| ID: 55550 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
Yes, not very efficient at all. On Windows at least with the standard gpu control utilities you can shove the power usage down and cut the boost clocks and save some power.You can do it under Linux as well. You know that. Judging by the relevant benchmarks: For MD simulations there's no point to upgrade the RTX 2080Ti to the RTX 3080. You get more performance in direct ratio of the power consumption. | |
| ID: 55552 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
I do know that. I was being terse and the main advantage of Windows utilities is the ability to undervolt. | |
| ID: 55556 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
Yes, not very efficient at all. On Windows at least with the standard gpu control utilities you can shove the power usage down and cut the boost clocks and save some power.You can do it under Linux as well. You know that. these aren't entirely relevant since FAH bench is an OpenCL benchmark and the apps here use CUDA. there is a bit of overhead in the conversion from OpenCL to CUDA, which is why CUDA runs faster on nvidia GPUs. FAH bench might be doing the same kinds of research and underlying calculations, but since it's not using CUDA it's not directly comparable to the CUDA apps here. a properly made CUDA 11.1 app should see significant performance increases, leveraging the double FP32 core architecture. the OpenCL apps might not be able to do the same. i still believe that when such an app comes, the 3080 WILL be better "per watt" than the 2080ti. ____________ | |
| ID: 55565 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
i still believe that when such an app comes, the 3080 WILL be better "per watt" than the 2080ti.I don't doubt that you believe in it. I believe in it to some (much lower) extent as well. However the extra FP32 cores are aimed at rasterization and/or raytracing tasks, as their data set could be easily processed this way, while molecular dynamics simulations are (most likely) not. Therefore I strongly suggest that no-one should invest in RTX 2080Ti -> RTX 3080 upgrades (for crunching) before we can do a reality check on every detail (with a CUDA 11 app), as all that is revealed so far says that the costs of such an upgrade won't return in the form of lower electricity bills or higher performance at the same running costs. (If someone is interested, I can post my arguments (again...) but it's rather TLDR, plus I don't like to repeat myself.) | |
| ID: 55580 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
From my reading of tech deep-dive at AnandTech on the Ampere arch, the extra *new* FP32 register is just another generic register like the original in Turing. | |
| ID: 55581 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
FP32 is FP32. Doesn’t matter what they are used for. They can be used for that operation. | |
| ID: 55582 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
FP32 is FP32. Doesn’t matter what they are used for. They can be used for that operation.Provided that they are working on the same piece of the data. That’s where the 2x performance figures come from. If the workload is primarily FP32 operations, then you can expect to see major speed improvements. This has been widely reported.I would add: in the case of some special workloads. Half of the FP32 cores can be used every cycle (the same number as Turing).Actually quite the opposite: the "extra" FP32 cores are exactly in the same data pipeline, as the "original" FP32 cores. The "original" FP32 core and the "extra" FP32 core reside within the same CUDA core. Just like the FP32/INT32 in Turing: the same core can't do a FP32 and INT32 operation simultaneously; unless they operate on the same piece of the data, but it's highly unlikely that such an "combo" (FP32+INT32) operation is ever needed. But in some cases two simultaneous FP32 operation on the same piece of data could be useful. | |
| ID: 55611 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
Sorry to say, but you are misinformed or have misinterpreted the specs. The 2x FP32 is the new data path. The Turing architecture features a new SM design that incorporates many of the features introduced in our Volta GV100 SM architecture. Two SMs are included per TPC, and each SM has a total of 64 FP32 Cores and 64 INT32 Cores. In comparison, the Pascal GP10x GPUs have one SM per TPC and 128 FP32 Cores per SM. The Turing SM supports concurrent execution of FP32 and INT32 operations  Nvidia realized that having an entire path dedicated to INT32 was not necessary in most cases since INT operations were only needed about 30% of the time. So they combined FP32/INT into its own path, and added a dedicated FP32 path to get more out of it. ____________ | |
| ID: 55612 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
I think Zoltan is a bit vague, that's why I find his point hard to understand. What I think he means: let's ignore the INT32 for a moment and only focus on the additional FP32 units. Which data can they work on? | |
| ID: 55613 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
RTX3070 is here and should appear in shops in 2 days. Availability could be better than for the bigger cards, but demand will probably be very high. | |
| ID: 55643 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Waiting for the compute results for the cards. Would be the correct comparison of compute performance against the RTX 2080 Ti since the wattages are comparable. | |
| ID: 55644 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
we need a proper CUDA 11.1+ app from GPUGRID before we can compare anything | |
| ID: 55645 | Rating: 0 | rate:
| |
|
ExtraTerrestrial Apes Volunteer moderator Volunteer tester Send message Joined: 17 Aug 08 Posts: 2705 Credit: 1,311,122,549 RAC: 0 Level Scientific publications | |
|
Sure. I was just mentioning the new release as it may make it easier for Toni to get access to a card. | |
| ID: 55648 | Rating: 0 | rate:
| |
|
eXaPower Send message Joined: 25 Sep 13 Posts: 293 Credit: 1,897,601,978 RAC: 0 Level Scientific publications | |
|
Well I tried and failed to get my hand on Ampere cards once again. | |
| ID: 55649 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
you have to go in-person (and usually at least a day in advance, waiting in line like black friday) to get the cards from Microcenter. you can't buy 30-series online. | |
| ID: 55650 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
well. my email came, order placed. | |
| ID: 55651 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Congratz Ian. Now you get to be the first guinea pig of a new app. | |
| ID: 55652 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
Ian, have you tried FAH scoring it yet? | |
| ID: 55654 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
Too bad that F@H is no longer on the BOINC platform so that points would apply. | |
| ID: 55655 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
I will receive the card next Thursday 11/5. | |
| ID: 55659 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
Thanks for pointing out the openCL vs CUDA factor, Ian. I didn't think about FAHcore using a different function. | |
| ID: 55660 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
I don’t participate in FaH. And from what I understand, their application is not CUDA, but rather OpenCL. At least FAHbench is.Well, I do. The present FAHcore 22 v0.0.13 is CUDA, though the exact CUDA version number used is not disclosed. folding@home wrote: As of today, your folding GPUs just got a big powerup! Thanks to NVIDIA engineers, our Folding@home GPU cores — based on the open source OpenMM toolkit — are now CUDA-enabled, allowing you to run GPU projects significantly faster. Typical GPUs will see 15-30% speedups on most Folding@home projects, drastically increasing both science throughput and points per day (PPD) these GPUs will generate. This post of mine earlier in this thread discussed the performance gain of switching FAHcore from OpenCL to CUDA. As NVidia helped them to develop this new app, and NVidia gives the largest support for the folding@home project of all the corporations, I suppose they did their best (i.e. it's using CUDA11 to get the most out of their brand new cards). Slightly supporting this supposition is that they asked us to upgrade our drivers, and that the ... core22 0.0.13 should automatically enable CUDA support for Kepler and later NVIDIA GPU architectures ...aligns with that CUDA 11 is backwards compatible with Kepler. Ian&Steve C. wrote: So it likely won’t see the most benefit from the new architecture. Having a CUDA 11.1 app is crucial for this.That's true, it's also crucial to make these cards usable for GPUGrid in any way. What I did do in order to try to test CUDA performance is ive recompiled the SETI special CUDA application for CUDA 11.1. And I have an offline benchmarking tool and some old SETI workunits so I can check relative CUDA performance between a 2080ti and the 3070.I'm really interested in those results! This should give me a good baseline of relative performance to expect with Ampere when the GPUGRID app finally gets updated.This is where our opinions sunder: SETI (and other analytical applications) are using a lot of FFTs, which could benefit from the "extra" FP32 units, while MD simulations are not. So I don't consider SETI as an adequate benchmark for GPUGrid. | |
| ID: 55661 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
Thank you for sharing your insight, Zoltan. I much appreciate your perspective and experience in DC. | |
| ID: 55662 | Rating: 0 | rate:
| |
|
bozz4science Send message Joined: 22 May 20 Posts: 109 Credit: 68,936,176 RAC: 0 Level Scientific publications | |
|
After the recent rollout of CUDA support on F@H, that I shared with you in the very same thread initially, there now exist specific CUDA cores that helped to increase performance of NIVIDA cards tremendously on F@H. As Zoltan pointed out, there are still many unknown variables around the provided data, so take the performance charts provided on their website. | |
| ID: 55663 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
if they get the CUDA changes into the FAHbench application, I’ll try it out. But last time I looked at it, the benchmarking app still only used opencl. When comparing something like two different cards you need to eliminate as many variables as possible. Using the standard FAH app without the control the run the same exact work units over and ove the best I could do is run run each card for a few months to get average PPD numbers from each. I’m just not willing to put that level of effort into it, when I can likely get the same results from a quicker benchmark. | |
| ID: 55668 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
I got my EVGA 3070 black today and did some testing | |
| ID: 55689 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
i attempted to build FAHbench with CUDA support (the information says it's possible), but I'm hitting a snag at configuring OpenMM. | |
| ID: 55690 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
I got my EVGA 3070 black today and did some testingThank you for all the effort you have put in this benchmark! Regrettably your benchmarks confirmed my expectations. Performance wise it's a bit better than I've expected (67.6%+10%~74.4% of the 2080 Ti). Power consumption wise it seems as of yet that it's not worth to invest in upgrading from the RTX 2*** series for crunching. | |
| ID: 55691 | Rating: 0 | rate:
| |
|
bozz4science Send message Joined: 22 May 20 Posts: 109 Credit: 68,936,176 RAC: 0 Level Scientific publications | |
|
Kudos to you! From what I understand so far, I have to support Zoltan's opinion. I really must stress that I am very keen on efficiency as that is sth that everyone should factor in their hardware decisions. | |
| ID: 55692 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
I got my EVGA 3070 black today and did some testingThank you for all the effort you have put in this benchmark! take it with a grain of salt so far, which is exactly why I made the disclaimer. as you yourself mentioned, the types of calculations are different, and if SETI is performing a large number of INT calculations than this result wouldn't be unexpected. Ampere should see the most benefit from a pure FP32 load, and according to your previous comments, GPUGRID should be mostly FP32. It could also be that source code changes might be necessary to take full advantage of the new architecture. the new SETI app has ZERO source code changes from the older 10.2 app, I simply compiled it with the 11.1 CUDA library instead of 10.2. that's why I was attempting to build a FAHbench version with CUDA 11.1, but I hit a snag there and will have to wait. I don't do FAH, but since users here have said that GPUGRID is similar in work performed and software used, the 3070 should perform on par with the 2080ti. check this page for a comparison: https://folding.lar.systems/folding_data/gpu_ppd_overall showing the F@h PPD of a 3070 *just* behind the 2080ti. at $500 and 220W, that makes sense. not as power efficient as I'd like, but pushing it beyond the 2080ti nonetheless ____________ | |
| ID: 55693 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
From the issue raised on the OpenMM github repo, it seems they let their SSL certificate expire back in September. | |
| ID: 55694 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
The compiler optimizations for Zen 3 haven't made it into any linux kernel yet either. GCC11 and CLANG12 are supposed to get znver3 targets in the upcoming 5.10 kernel next April for the 21.04 distro release. | |
| ID: 55695 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
got the 3070 up and running on Einstein@home for some more testing. | |
| ID: 55720 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
|
I wonder if you slowed down the 2080Ti (reducing GPU voltage accordingly as well) by 20% to match the speed of the 3070, would it be about the same effective? (or even better in the case of GW tasks) | |
| ID: 55731 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
the 2080ti was already power limited to 225W. its not possible (under Linux) to reduce the voltage. there are just no tools for it. reducing the power limit will have the indirect effect of reducing voltage, but I don't have control of the voltage directly. I could power limit further, but it will only slow the card further. you start to lose too much clock speed below 215-225W in my experience (across 6 different 2080tis). the 2080ti was also watercooled with temps never exceeding 40C so it had as much of an advantage as it could have had. | |
| ID: 55732 | Rating: 0 | rate:
| |
|
SolidAir79 Send message Joined: 22 Aug 19 Posts: 7 Credit: 168,393,363 RAC: 0 Level Scientific publications | |
|
Any apps i can use yet on my 30s cards? | |
| ID: 56525 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
Any apps i can use yet on my 30s cards? nope. ____________ | |
| ID: 56527 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
https://www.gpugrid.net/workunit.php?wuid=27026028 | |
| ID: 56590 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
|
I've "saved" a workunit earlier (my host was the 7th crunching it - the 1st successful one). It had been sent to two ampere cards before. | |
| ID: 56601 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
i have a couple like that that I similarly saved. even some _7s (8th) | |
| ID: 56604 | Rating: 0 | rate:
| |
|
Is there any update regarding nVidia Ampere Workunits?? | |
| ID: 57019 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
my 3080Ti (limited to 300W mind you) did this ADRIA task in under 9.5hrs | |
| ID: 57355 | Rating: 0 | rate:
| |
|
Boca Raton Community HS Send message Joined: 27 Aug 21 Posts: 36 Credit: 2,958,481,809 RAC: 17,078,624 Level Scientific publications | |
|
I am not running 3090s or 3080ti cards but I do have some times/comparisons for high-end Turing and Ampere GPUs for Adria tasks. | |
| ID: 57980 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
I am not running 3090s or 3080ti cards but I do have some times/comparisons for high-end Turing and Ampere GPUs for Adria tasks.The NVidia Quadro RTX 6000 is a "full chip" version of the RTX 2080Ti (4608 vs 4352 CUDA cores) while the NVidia RTX A6000 is the "full chip" version of the RTX 3090 (10752 vs 10496 CUDA cores). The rumoured RTX 3090Ti will have the "full chip" also. The RTX 3080 Ti has 10240 CUDA cores. (The real world GPUGrid performance of the Ampere architecture cards scales with the half of the advertised number of CUDA cores). | |
| ID: 57995 | Rating: 0 | rate:
| |
|
Boca Raton Community HS Send message Joined: 27 Aug 21 Posts: 36 Credit: 2,958,481,809 RAC: 17,078,624 Level Scientific publications | |
Is that true for all NVidia GPUs or just Ampere? Just out of curiosity, why is it this way? | |
| ID: 57996 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
Just guessing here but since every new generation of Nvidia cards has basically doubled or at least increased the CUDA core count and since the GPUGrid app as well as a very few other project apps are really well coded for parallelization of computation, you can state that the crunch time scales with more cores. | |
| ID: 58002 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
It's true only for the Ampere architecture.(The real world GPUGrid performance of the Ampere architecture cards scales with the half of the advertised number of CUDA cores). 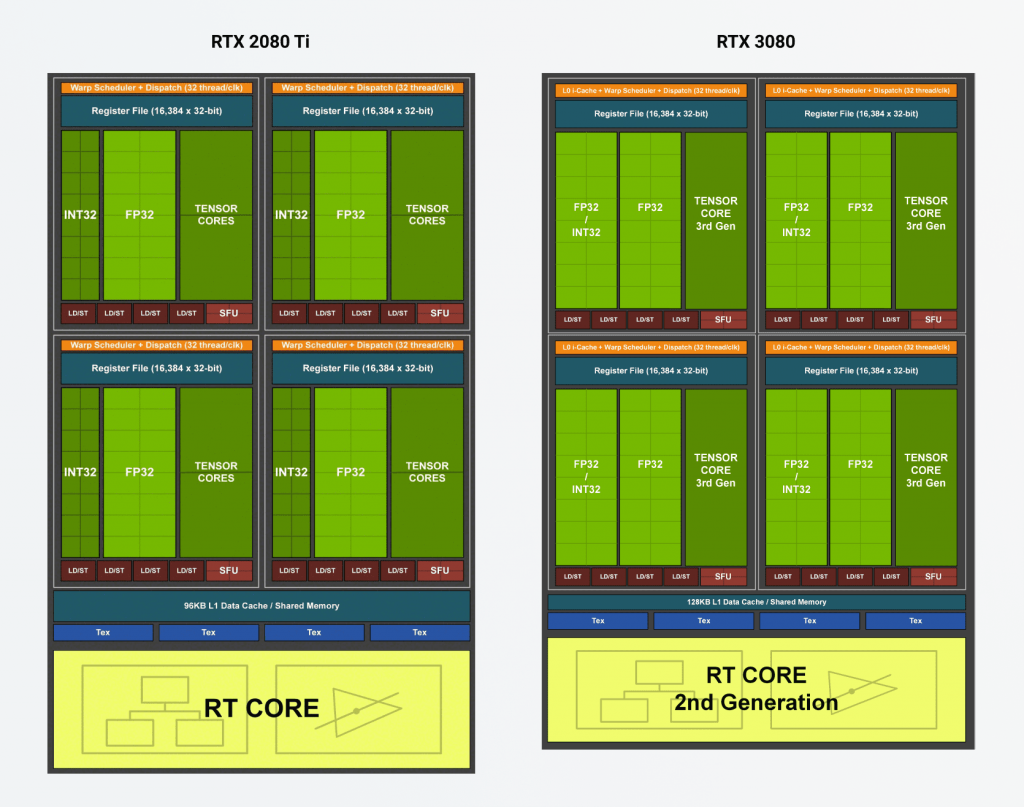 As you can see on the picture above, the number of FP32 units have been doubled in the Ampere architecture (the INT32 units have been "upgraded"), but it resides within the (almost) same streaming multiprocessor (SM), so it could not feed much better that many cores within the SM. From a cruncher's point of view the number of SMs should have been doubled as well (by making "smaller" SMs). The other limiting factor is the power consumption, as the RTX 3080Ti (RTX3090 etc) easily hits the 350W power limit with this architecture. https://www.reddit.com/r/hardware/comments/ikok1b/explaining_amperes_cuda_core_count/ https://www.tomshardware.com/features/nvidia-ampere-architecture-deep-dive https://support.passware.com/hc/en-us/articles/1500000516221-The-new-NVIDIA-RTX-3080-has-double-the-number-of-CUDA-cores-but-is-there-a-2x-performance-gain- | |
| ID: 58003 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
As long as you can keep an INT32 operation out of the warp scheduler, then Ampere series can do two FP32 operations on the same clock. | |
| ID: 58005 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
|
and since the real performance doesn't scale with the FP core count, that leads us to the conclusion that the GPUGRID app must be coded with a fair number of INT operations which cut into the FP cores available (half of the FP cores are actually shared FP/INT cores and can only do one type of operation at a time, while the other half are dedicated FP32). This explains the massive performance boost of Turing cards over Pascal (at the same FP count) for GPUGRID since Turing introduced concurrent FP/INT processing. the Turing SM adds a new independent integer datapath that can execute instructions concurrently with the floating-point math datapath. In previous generations, executing these instructions would have blocked floating-point instructions from issuing Einstein scales much better with FP core count on Ampere, but is also more reliant on memory speed/latency than GPUGRID. if you take this "only half" rule, it's doesn't stack up with real world gains seen on Einstein. A 3080Ti is 70-75% faster than a 2080Ti on Einstein. while under the 1/2 rule "only" has 17% more cores. so one obviously can't paint with such a broad brush to include all of crunching. all depends on how the app is coded to use the hardware, and sometimes you can't make an app totally optimized for a certain GPU architecture depending on what kinds of computations you need to do or what coding methods you use. ____________ | |
| ID: 58009 | Rating: 0 | rate:
| |
|
Retvari Zoltan Send message Joined: 20 Jan 09 Posts: 2343 Credit: 16,201,255,749 RAC: 698 Level Scientific publications | |
... the GPUGRID app must be coded with a fair number of INT operations which cut into the FP cores available (half of the FP cores are actually shared FP/INT cores and can only do one type of operation at a time, while the other half are dedicated FP32).Perhaps MD simulations don't rely on that many INT operations, so it's independent from the coder and from the cruncher's wishes (demands). Einstein scales much better with FP core count on Ampere ...The Einstein app is not a native CUDA application (it's openCL), it's not good at utilizing (previous) NVidia GPUs, making this comparison inconsequential regarding the GPUGrid app performance improvement on Ampere. It's the Ampere architecture that saved the day for the Einsten app, so if the Einstein app would be coded (in CUDA) the way it could run great on Turing also, you would see the same (low) performance improvement on Ampere. all depends on how the app is coded to use the hardware, and sometimes you can't make an app totally optimized for a certain GPU architecture depending on what kinds of computations you need to do or what coding methods you use.Well, how the app is coded depends on the problem (the research area) and the methodology of the given research, and the program language, which is chosen by the targeted range of hardware. The method is the reason for the impossibility of "the GPUGRID app must be coded with a fair number of INT operations" demand. (FP32 is needed to calculate trajectories.) The targeted (broader) range of hardware is the reason for Einstein is coded in openCL, resulting in lower NVidia GPU utilization on previous GPU generations. | |
| ID: 58017 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1035 Credit: 37,393,007,483 RAC: 73,489,569 Level Scientific publications | |
... the GPUGRID app must be coded with a fair number of INT operations which cut into the FP cores available (half of the FP cores are actually shared FP/INT cores and can only do one type of operation at a time, while the other half are dedicated FP32).Perhaps MD simulations don't rely on that many INT operations, so it's independent from the coder and from the cruncher's wishes (demands). Nvidia cards only run CUDA. OpenCL code gets compiled into CUDA at runtime. But just using OpenCL doesn’t mean that it can’t effectively use the GPU, it’s all in the coding. The compiling to CUDA at runtime only provides a very small overhead. A new Einstein app was released several months ago which I was involved in the testing and development. Mostly coded/modified by another user (petri, the same guy who wrote the SETI special CUDA app), and then I forwarded and explained the changes to the Einstein devs for integration and release. It’s now available to everyone and provides big gains in performance for all Nvidia GPUs all the way back to Maxwell architecture, so yes the new coding applies to Turing also and Ampere saw major gains over Turing. But Ampere by far had the best gains. Maxwell and Pascal cards see about a 40% improvement over the old app, Turing about 60% improvement, and Ampere had over 100% improvement. It basically puts Nvidia back on level ground or even ahead of AMD for Einstein. The issue was a certain command and parameters being used, which caused memory access serialization on Nvidia GPUs, effectively holding them back. Petri recoded it a different way to basically remove the limiter, parallelize the memory access and allow the GPU to run full speed. So yes, it’s relevant and shows how different code can be used for the exact same computation to utilize the hardware better and increase performance. Also shows how you can’t say that you can only figure “half” of the cores for all of crunching when Ampere performance when it clearly has benefits that’s scale much closer to the FP core count with certain projects. If you look at the Ampere architecture and understand it, you’ll see that the only reason that “half” of the FP cores wouldn’t be used, is if INT operations are running. regarding GPUGRID's app, if you observe the behavior of what the app is doing with the hardware, you'll see that one trait stands out from most other projects, high PCIe bus utilization. the app is sending A LOT of data over the PCIe bus, equivalent to almost a full PCIe 3.0 x4 worth of bandwidth, for the whole run. The app is coded in a way where lots of data is being sent between the CPU and the GPU over the PCIe bus, but very little stored in GPU memory. these kinds of operations usually involve a lot of integer adds for data fetching as well as for FP compares or min/max processing. So while the meat of the computation is for trajectories, there are a lot of other things that the app needs to do in INT to get and send the data and organize the results. I imagine that if the devs changed their code philosophy to store more data in GPU memory, they could cut out a lot of the excess involved in sending so much data over the PCIe bus, keep things more local to the GPU, and speed up processing overall. This would have the caveat of excluding some low VRAM GPUs however. ____________ | |
| ID: 58018 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1288 Credit: 5,139,031,959 RAC: 9,910,176 Level Scientific publications | |
|
👏👍 | |
| ID: 58019 | Rating: 0 | rate:
| |


{kind=link}
{kind=link}
{kind=link}
Message boards : Graphics cards (GPUs) : Ampere 10496 & 8704 & 5888 fp32 cores!